ARMベース・システムLSI開発の事例研究 ――CPUの選択,バス構成,グラフィックス処理やビデオ表示制御の取り扱い
● 描画動作は矩形領域を別の位置に移すBitBltが基本
GDPは,グラフィックス制御のうちの描画動作を受け持ちます.描画処理はフレーム・メモリへの絵の書き込みの作業であり,CPUとGDPが互いに協調して実行していきます.CPUはおもに材料作りを受け持ちます.JPEG画像の展開やベクトル図形(直線,円弧など)の作成を行い,ワーク・メモリ上に準備します.GDPは,この完成した材料をフレーム・メモリ上の指定された座標に転送します.材料は1度作成すると,何回でも使い回しができます.一方,フレーム・メモリにアニメーション(動画)として描画する作業は毎フレーム必要です.ここでGDPの性能が生きてきます.
GDPの転送の基本は,図8(a)に示したBitBlt(ビットブリット)(bit block
transfer)です.これは,ある矩形領域の図形を別の位置に転送するものです.図8(a)はまったくそのままのサイズで転送していますが,拡大・縮小したり回転したりしながら転送することも,グラフィックスのコンテンツでは頻繁に起こります.このため,GDPは図8(b)のようにアファイン変換処理注を伴うBitBlt転送をサポートしています.
アファイン変換とは,例えば,元絵を角度θだけ回転し,X方向にsx倍,Y方向にsy倍伸縮させ,かつX方向にTX,Y方向にTYだけ並行移動させる,といった図形処理です.このケースでは,元絵(ソース・ピクセル)内の各座標(X1,Y1),転送先(デスティネーション・ピクセル)の各座標を(X2,Y2)とすると,下記の関係になります.
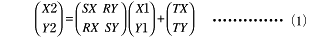
ただし,
SX=sx×cosθ,RY=sx×(-sinθ)
RX=sy×sinθ,SY=sy×cosθ
です.図8(b)のSRC_RECT内の各ピクセルが転送先のどこに位置するかをすべての点に対して演算する必要があり,CPUで処理すると非常に時間がかかります.本LSIでは,これをハードウェア(GDP)で実現して性能を確保しています.
なお,アファイン変換において,ソース側のピクセル値のアファイン変換後の座標を計算してそこに転送するだけですと,拡大転送時などに転送先ピクセルがすべて埋まらず,歯抜けになることがあります.このためGDPでは,転送先を囲む最大矩形範囲内(DST_RECT)の全ピクセルに対して逆アファイン変換を施して,ソース側のどのピクセルに対応するかを見てからDST_RECT内のピクセルを埋めています.これにより歯抜けになることを防げます.
注;アファイン(affine)変換はアフィン変換と呼ばれることもある.
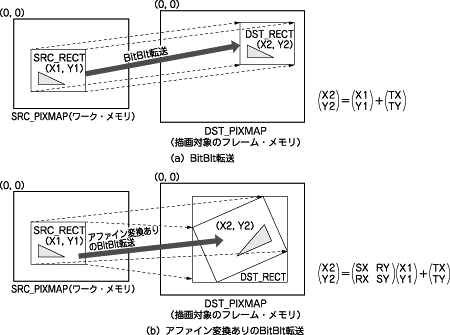
図8 BitBltとアファイン変換
(a)はシンプルなBitBlt転送である.SRC_PIXMAP中の任意位置・任意サイズの長方形の内部ピクセルを,DST_PIXMAPの任意位置に同じサイズで転送する.(b)はアファイン変換を伴うBitBlt転送である.拡大縮小と回転を行いながら,SRC_PIXMAP中の任意位置・任意サイズの長方形SRC_RECTの内部ピクセルをDST_PIXMAPに転送する.


