PLD デバイス・アーキテクトの決断 ――Altera社 ARM-based Excalibur の場合
図4のブロック図には,CPUから2種類のメモリへのメモリ・アクセス・パスも示されています.「パスC」はCPUからデバイスのプログラマブル・ロジック部に組み込まれたメモリ(ESBで構成)までの経路,「パスD」はCPUからハードIPのプロセッサ・サブシステムの一部であるメモリ(デュアルポートSRAM)までの経路です.前述の例と同じように図4のテスト・デザインをARM-based Excaliburデバイスに実装し,三つの異なるソフトウェア・ベンチマークによって性能を評価しました.このベンチマーク・テストは,一般的に使用されるデスクリプタやデータ処理などの機能と,リファレンスの偏りが少ないテーブル参照から構成されています.
得られた結果を図6に示します.ソフトウェア・ベンチマークによれば,デバイスのプログラマブル・ロジック部のメモリを使用した場合(図6の濃い灰色のグラフ)と比較すると,ハードIPのプロセッサ・サブシステムのデュアルポートSRAMを使用した場合(図6の薄い灰色のグラフ)は2~4倍の速度で動作するという結果 が得られました.「パスB」では,その目的地に到着するためにプログラマブル・ロジック部の配線リソースを使用する必要があるので,前者と比較すると,性能により大きな差が出ると予想されます.これに対して,「パスD」は全体がハードIPのプロセッサ・サブシステム内にあるため,専用のシリコン・リソースを使用できるという利点があります.
これらの測定値は特定のプログラマブル・デバイスに関するものですが,同じような構成を持つデバイスのすべてについて,これと同じことが言えます.PLDアーキテクチャの進化によって,今後のデバイス・ファミリでは,ここに説明されているメモリ・アクセスなどの遅延が大幅に減少することは確かです.しかし,半導体プロセスが同じであれば,ハードIPによるプロセッサ・サブシステムは,まったく同じ機能をプログラマブル・ロジックに実装した場合よりも,つねに性能的に優れていることになります.
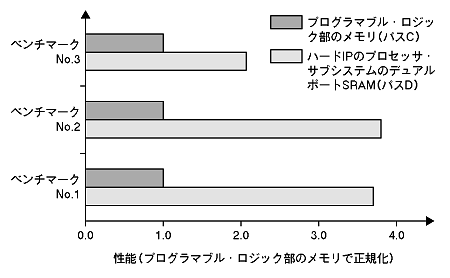
〔図6〕ARM-based Excaliburのメモリ・アクセス相対性能
薄い灰色のグラフは,ハードIPのプロセッサ・サブシステムのデュアルポートSRAMへのCPUアクセス速度を示す.濃い灰色のグラフは,プログラマブル・ロジック部のESBメモリへのCPUアクセス速度を示す.ここでは,各ベンチマークのESBメモリへのCPUアクセス速度の値で正規化している.グラフの棒が長ければ,それだけ高速であることを意味する.


