マルチプロセッサLSIに適したオンチップ・ネットワーク ――ダイレクト・データフロー・インターコネクト
● マルチマスタ時のオーバヘッド
図1では,バス・マスタと呼ばれるバス・トランザクションを開始するモジュールが複数存在します.プロセッサやDMA(direct memory access)などがバス・マスタ・モジュールの代表です.
このような場合,一般にアクセスを調停するアービタが必要になります.複数のバス・マスタから同時にアクセス要求があった場合,アクセス権をとれなかったモジュールは待たされることになります(図2(a)).つまり,アクセス遅延(オーバヘッド)が生じます.また,SDRAMなどへのアクセスの場合,メモリ・アクセスの遅延も加わり,アクセス遅延はますます大きくなります.
複数のマスタがアクセスするということは,必然的にデータの転送量が増大します.例えば,二つのプロセッサを用いてマルチメディア処理を行う場合,データをプロセッサ間で共有することが考えられます.共有メモリはバス上に置かれ,複数のマスタによる共有メモリへの読み書きが繰り返されます(図2(b)).これが,マルチプロセッサ(マルチマスタ)システムにおけるデータ転送のオーバヘッドとなります(コラム「バス性能がシステム性能を決める」を参照).
処理ユニット(プロセッサ,ハードウェア・モジュール)を100%動作させるには,データ,命令(プログラム,コントロール)が途切れることなく各ユニットに供給できなくてはなりません.データ・バスの容量(最大データ転送量)や最大遅延を考慮して,バッファリングやスケジューリングを行うわけですが,それらの見積もりは簡単ではありません.しかも,設計途上の仕様変更(おもに機能追加)が頻繁に行われるため,ますます見積もりは困難になっています(コラム「バスの性能を上げる」を参照).
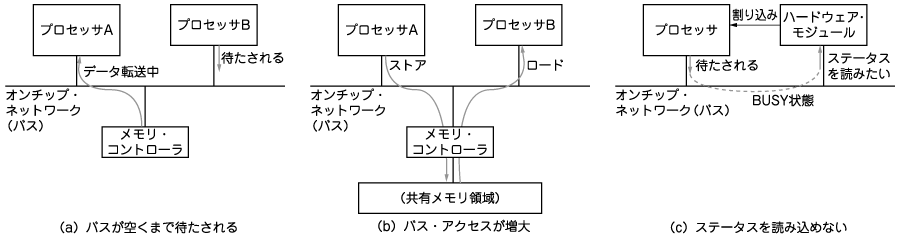
図2 バス・システムで起こる問題の例
(a)におけるプロセッサBの要求は,プロセッサAのデータ転送が終了するまで待たされる.プロセッサBが次にバスを獲得できる保証はないので,プロセッサBは長時間待たされるかもしれない.すると,プロセッサBの実質演算能力が低下することになる.(b)のように,共有メモリを通してデータのやり取りを行うと,バス・アクセスが増大する.(c)のように,ハードウェア・モジュールが割り込みを発生すると,プロセッサはハードウェア・モジュールのステータスを読み込んで次のコマンドをセットしようとする.プロセッサはシステム・バスを介してアクセスするが,バスの状態によっては待たされる可能性がある.すると,ハード・リアルタイムの(時間に対して非常に厳しい)システムでは,要求される時間制約を満足できずシステム・フェイルになる.


