マルチプロセッサLSIに適したオンチップ・ネットワーク ――ダイレクト・データフロー・インターコネクト
●○● Column 3 ●○●
FLIXの概要
Xtensa LXのもう一つの重要な技術であるFLIXについて簡単に解説します.詳細はTensilica社のホームページ(http://www.tensilica.com/)などを参照してください.
プロセッサの演算能力を高める方法にはアーキテクチャ・レベル(ISA:Instruction Set Architectureレベルと呼ばれることもある)とマイクロアーキテクチャ・レベル(おおざっぱには,実際の設計時に検討するレベル)の方法があります.これらの境界はきれいに分けられるものではなく,非常にあいまいです.例えば学術的に考えるとパイプライン,キャッシュなどはマイクロアーキテクチャ・レベルになるのですが,キャッシュをアクセスする命令(とくに初期化のための命令)は通常必要になるので,ちょっと矛盾しそうです.プロセッサによってはキャッシュ・アクセス命令などを特別扱い(互換性を保証しないなど)するケースもありますが,あいまいであることに違いはありません.
さてプロセッサの処理能力を高めるには,
1) 1クロックでできるだけたくさんのことを実行させる
2) 1クロックでできるだけたくさんのデータを処理する
3) ロスを少なくする
4) クロック周波数を上げる
が大きな要素になります.4)は実際の設計によるので,マイクロアーキテクチャの領域と言えるでしょうか.クロック周波数を上げる方法は非常に有効ですが,クロック周波数を上げ続けることは消費電力などの要素まで絡めて考えると非常に難く,ASIC設計のフローではおのずと限界があります.
1)については,例えばいわゆるCISC型アーキテクチャのプロセッサには複雑な演算を実行する命令があったので,それを1クロックで実行できればRISC型アーキテクチャのように簡単な命令語ベースのプロセッサと比較して効率が良いといえます.また,命令に要するメモリも節約できます.RISCの概念では二つの値の差をとって差の絶対値を求めるという演算は2命令で実行することになります.しかし,アプリケーションでこの演算を多用することがわかっている場合,差の絶対値を求める演算命令があれば,処理効率を高められるうえ,メモリも節約できます.クロック周波数の問題も出てきますが(差を求めるだけの演算のほうがやはり速くできる),1クロックでできるだけたくさんのことを実行させるには有効な方法です.
これとは別に,スーパスカラと呼ばれる,1クロックで複数の命令語を同時に実行する方法があります.これは,RISC型プロセッサが処理効率を上げるときの方法として大きく発達しました.2,4,8個のデコーダ,演算ユニットを持たせ,同時に複数命令を実行させようという発想ですが,分岐命令などが存在するため,つねに並列実行できるわけではなく,しかも処理がかなり大掛かりになるため,組み込み用途のプロセッサではあまり見かけません.スーパスカラはマイクロアーキテクチャに属するといえるでしょう.
VLIWはこの発想をアーキテクチャ・レベルで実現したといえるかもしれません.通常のプロセッサの命令語はたかだか32ビットですが,VLIWでは128ビットや256ビットといった非常に長い命令語を使います.命令語をいくつかのスロットに区切り,スロットごとに演算を割り当てます.もっとも各スロットにつねに有効な演算を割り当てることは難しく,しばしばNOP(何もしない)演算を割り当てることになります.
2)については,例えばベクトル量を同時に扱えれば,行列演算を多用するアプリケーションなどで処理能力が格段に向上します.スーパコンピュータで花開いたアーキテクチャですが,Intel社のMMXをはじめとしたマルチメディア・アプリケーション用途でこの手法はかなり一般的になっています.
3)については,ハイエンドのプロセッサでは分岐予測といった複雑な技術を実現しています.分岐予測はマイクロアーキテクチャに属する要素なのですが,コンパイラは分岐ロスや分岐予測についてもよく認識している必要があります.
おもしろいもので,コンパイラはアーキテクチャを逸脱することはできません.しかし,マイクロアーキテクチャをよく理解していないと性能を引き出すことはできません.事実,コンパイラをバージョンアップすると,処理能力が向上することがあります.
現在のところ,本プロセッサ・アーキテクチャはスーパスカラ構成をとっていません.回路規模が非常に大きくなるためです.また,分岐予測のような複雑なマイクロアーキテクチャ構造もとっていません.パイプラインは至ってシンプルです.本プロセッサではシステム・エンジニアがアプリケーションに最適な命令語を定義できます.上述した差の絶対値を求めるという命令やさらに複雑な演算の定義も可能です.ここで注意していただきたいのは,「複雑な演算」イコール「回路が複雑で遅い」,ということがかならずしも成立しないことです.アプリケーションに最適な命令語を定義することで,処理能力を何十倍にも高めることが可能です.また,データ・タイプを新たに定義することもできるので,ベクトル・タイプのデータを定義すると,データの同時処理(SIMD)も実現できます.
さて,本プロセッサは,FLIXと呼ぶ新たに発展したVLIWの考えかたに属する技術を採用しています.Xtensaで定義できるのは16ビット,24ビットの命令語ですが,本プロセッサではこれらに加えて64ビット(もしくは32ビット)の命令語も定義できます.64ビットの命令語のフォーマットは不定であり,ユーザがほぼ自由に定義できます.複数のスロットに分けることもできれば,一つのスロットとして扱うこともできます.1スロットのフォーマットである場合,より長いイミディエートや複数のテーブル変数を扱うといった命令を定義できるようになります.もちろん複数フォーマットを指定することも可能です.
FLIXと通常のVLIWを比較した場合の大きな相違は,VLIWでしばしば発生するNOP命令挿入をFLIXではほとんどなくすことができることです.VLIWは命令語長が固定ですが,FLIXアーキテクチャのプロセッサは16,24,64ビットという3種類のフォーマットを持つため,NOPの挿入を極力回避できます(図A-1).
ユーザは明示的に各スロットを定義できます.いくつのスロットに分けるかだけを指定すれば,ツールが自動的にスロットを定義するので,ユーザの手を煩わせることはありません.各スロットはあらかじめ開発元が用意した命令を使用することもできます.実際にコンパイラは,図A-1に示したような三つの24ビット命令を一つの64ビット命令にまとめることもします.24ビット×3は72ビットであり,64ビットには収まらないように見えます.しかし,同じ演算を行うだけで命令語のフォーマットはかならずしも元の24ビットのフォーマットと同じである必要がないため,このようなことが可能になります.
本プロセッサといっしょに提供されるコンパイラ(C,C++)はFLIXをサポートしています.そのため,ユーザはFLIXを意識せずにプログラムを書くことができます.コンパイラはプログラムを解析し,性能とコード・サイズを最適化したバイナリ・コードを出力します.FLIXオプションをONにすることで,同じソース・コードでも数十倍の性能向上が図れます.FLIXの技術とユーザ独自の実行命令を定義すること,データ・タイプを定義することなどで,本プロセッサは従来のプロセッサ・コアの何十倍もの演算性能を得ています.
このような演算能力の高いプロセッサに途切れることなくデータを供給する一つの手法がTIEポートなのです.
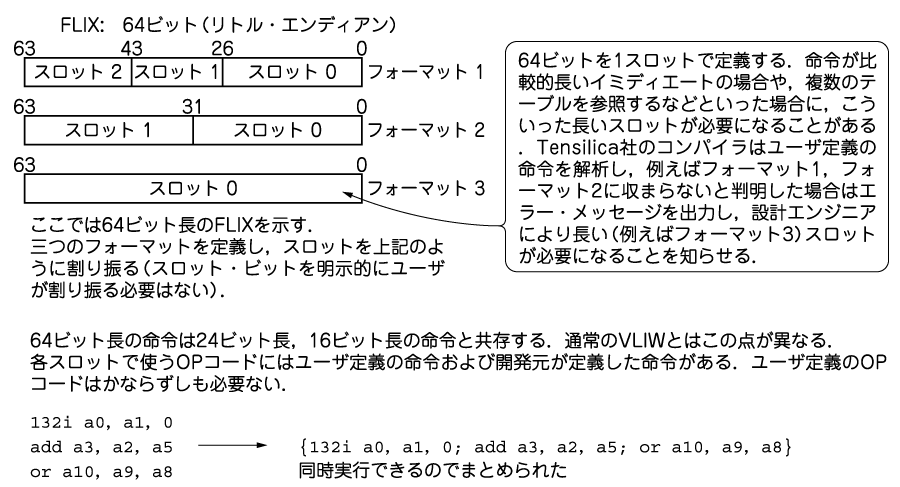
図A-1 FLIX
三つのコア命令を,FLIX技術を用いて64ビットの1命令として実行するようにした.このようにXtensa LXのコンパイラはソース・コードを解析して,実行とプログラムのコード・サイズの最適化を行う.この例では三つのコア命令を一つにまめるため,実行性能が上がる.また,三つの24ビット命令を64ビットにまとめるので,メモリも節約できる.


