民生機器向けSOC開発と先端的セキュリティ処理のIPコア化 ―― CyberWorkBenchの活用事例
tag: 半導体 ディジタル・デザイン
技術解説 2009年7月 2日
● ステップ1:C言語を軸に専門家のコラボ体制を構築
それでは,以上のような障壁をどのように乗り越えていったかを説明します.
まず最初に,セキュリティ側と回路設計側が仕様書だけを介して接する開発体制を止め,密にコラボレーションする体制へ切り替えました(図10).開発作業を,
- セキュリティ側で処理のC/C++へのブレークダウンとテスト・データ作成を行う
- 基本アーキテクチャ設計やアルゴリズム修正を両者共同(ここが重要)で行う
- ハードウェア全体のインテグレーションや論理合成以降の作業を回路設計側で行う
という形で進めることにしました.
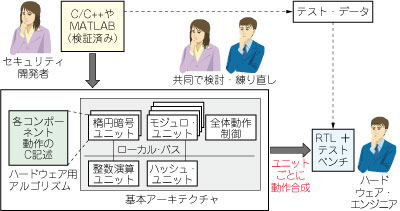
図10 専門家の個ラボ体制
1.セキュリティ側で処理のC/C++へのブレークダウンとテスト・データ作成を行う.
2.基本アーキテクチャ設計やアルゴリズム修正を両者共同(ここが重要)で行う.
3.ハードウェア全体のインテグレーションや論理合成以降の作業を回路設計側で行う.
この体制をうまく機能させる鍵となったのが,Cベース設計です.セキュリティ側と回路設計側がC言語を共通言語として用いることで,意志疎通が大変スムーズになりました.回路設計側では,仕様書にありがちな疑似コードではなく,本当に動作するCコードを見ることで,データ・フローや回路構成について具体的なイメージを持てるようになりました.テスト・データ作成の心配が解消されたのも素晴らしい点です.また,セキュリティ側では,回路化時に支障が出る個所をCコード上で具体的に知ることができるようになりました.
もちろん,Cベース設計を利用したからといって,100%の相互理解ができるわけではありません.しかし利用しなければ,回路作成に必要な情報の交換すら難しくなるところでした.
● ステップ2:実装前段階としてのソフト用C修正
さて,セキュリティ側でグループ認証ソフトウェアを作成して,パソコン上で機能検証を済ませました.しかし,このソフトウェアを一気に動作合成にかけるようなことはできません.回路実装の前段階として,次の修正と再検証が必要になりました(図11).修正後の動作合成用Cは,約15000行の総量になりました.
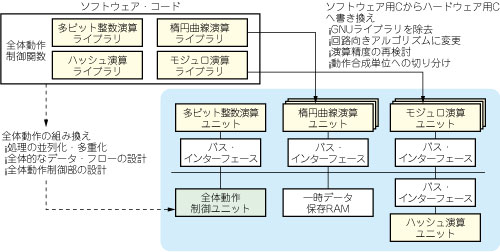
図11 回路実装のためのCコードの修正
ソフトウェア用のCコードからハードウェア用のCコードへの書き換えが必要.アルゴリズム変更や基本アーキテクチャ決定を行う.動作合成はユニット単位で行う.
- パソコン用ソフトウェアではさまざまな公開ライブラリをリンクして使うことが珍しくありませんが,そうしたライブラリ中の演算をスクラッチで作ります.今回は,公開の多ビット長演算ライブラリ(GNU MP)を使わずに済ますよう,改造が必要でした.
- データの流れ方,メモリの使い方,演算アルゴリズム,関数階層構造などを,ハードウェアに合った形へ修正します(7).要求性能を達成するうえで一番重要なのが,このような大粒度(ユニット・レベル)での処理修正で,後のステップ3で行います.
- 動作合成はユニットごとに行います.ユニット内部の処理も見直します.今回多用する楕円暗号演算やモジュロ演算(RSA)では,高速ソフトウェア用Cコードをただ回路化してもプロセッサ+α程度の速度にしかならないので,図12のような最適化が必要です.また,回路ではメモリ・アロケーション,動的ポインタ,再帰などが使えないので,これらを排除しなければなりません(メモリ上に置いたデータに対する処理であるため).今回は,入り組んだデータ構造を除去し,分割統治法による高速演算アルゴリズムの再帰を展開する,といった対応が必要でした.
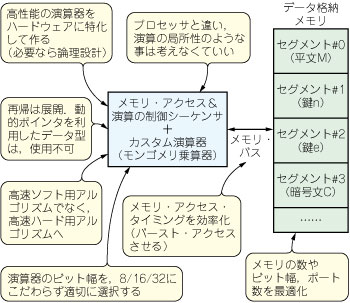
図12 小粒度の処理の見直し
高速ソフトウェア用のCコードをただ回路化してもプロセッサ+α程度の速度にしかならない.アルゴリズム変更やハードウェア向けの最適化が必要になる.
以上は決して単純作業ではなく,かなり手間がかかりました.「なんだ,Cベース設計をしても大して意味がないではないか」と思われるかもしれません.しかし,そうではありません.
これらの処理見直しは,従来のRTL設計でも必要だった作業です.従来はそれを回路設計側が行わざるを得なかったのですが,Cベース設計導入によりセキュリティ側でできるようになったことが大きな変化です.処理内容を熟知しており大胆なアルゴリズム変更もできる専門家と,小手先の修正しかできない非専門家とでは,修正の正確さや改善の度合いが如実に異なります.
● ステップ3:性能見積もりと基本アーキテクチャ検討
ステップ2と並行して,回路の基本アーキテクチャ検討を進めました.
加算器や乗算器で数十ビットのデータを加工する,といった処理粒度ならば,回路化を動作合成にだいたい任せられます.しかし,楕円曲線演算ユニットやモジュロ演算ユニットでブロック・データやデータ・ストリームを処理する,という大きな粒度(いわゆるESLや,その少し下)に対しては,実用的な自動設計ツールがまだありません.従って,所定の回路性能を達成するために,「各ユニットを何個用い,どのように接続し,どのようにデータを流し,全体動作をどう制御するか」を人が事前に検討しなければなりませんでした注7(図13).検討のためには,各ユニットの処理速度・回路規模や入出力データの量・インターバルをなるべく正確に予測する必要があります.
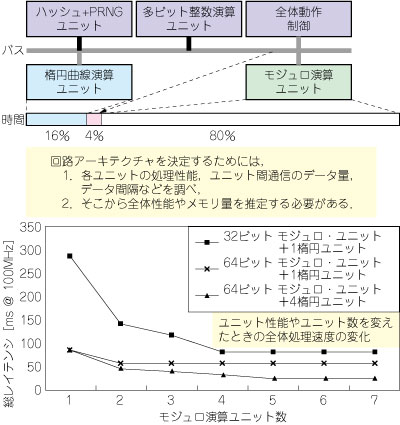
図13 性能見積もりと基本アーキテクチャ検討
各ユニットを何個用い,どのように接続し,どのようにデータを流し,全体動作をどう制御するかを検討する.
注7: いちばんやってはいけないのは,処理全体を動作合成にかけて闇雲にオプションを変えてみることや,全体を考えずに各ユニットを先に作ってしまい,統合時にアドホックにつじつまあわせをしようとすること.


