無償IPコアでよく分かるPCI ExpressのFPGA実装技術 ―― 知っておきたいIPコア実装のキモ
本稿ではFPGAに回路を実装し,転送性能を最大限に引き出す方法について解説する.筆者が開発した無償IPコアを用いた性能実測例を紹介する.(筆者)
1.転送速度の実測
本稿では実際にIP(Intellectual Property)コアを実装した回路を用いて転送性能を測定し,転送性能を最大限に引き出す方法について解説します.
PCI Express転送性能の測定には,K&F Computing Research(以下,KFCR)の無償IPコア「GPCIe」を使用します.IPコアを実装するハードウェアには同社のx8対応評価ボードを使用します(写真1).

写真1 性能測定に使用したPCI Express (x8) 評価ボードの外観
K&F Computing Research製.FPGA(Altera社 Arria GX)と外部メモリ(DRAM)を搭載.Arria GXでリンク幅x8をサポートする唯一のボード(筆者調べ).
この評価ボードは,高速トランシーバを内蔵した米国Altera社のFPGA「Arria GX(EP1AGX60EF1152)」を1個搭載しています.Arria GXは高速トランシーバを内蔵した品種の中では比較的低価格で,Altera社ではこれをミッドレンジFPGAと位置付けています.Stratix II GXの廉価版と考えてよいでしょう.Altera社ではリンク幅x8レーンの動作はStratix II GX(およびStratix IV)でのみ保証しており,Arria GXに関してはx4までしか保証していません.しかし後述のように,本IPコアでは技術上の工夫によってx8での動作を実現しています.
FPGA内部には,IPコアのほかに性能測定のためのメモリを実装します.ボード上にはDRAMが搭載されていますが,今回はあえて使用しません.これはDRAMインターフェースの転送性能が測定結果に影響を与えることを避けるためです.評価ボードを接続するホスト・パソコンとしてはCPUにIntel社のCore2 Quad(Q6600,2.4GHz動作),チップセットに同社のX38 Expressを搭載したパソコンを使用します.測定用システム全体の構成は図1のようになります.
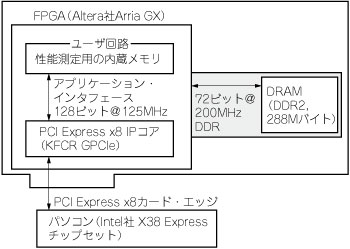
図1 性能測定に使用したハードウェアの構成
評価ボードに搭載されているFPGA内に,PCI Express IPコアと性能測定用のメモリ(FPGA内蔵)を実装した.ボード上の外部メモリ(網掛け部分)は今回の実測では未使用.
このシステムを用いた転送性能の測定結果を図2に示します.PIO read/write,DMA read/writeの計4種類のデータ転送方式を用いて,10バイトから64Kバイトまでの転送データ・サイズについて得られた転送性能をプロットしてあります.図2の(a),(c)は上り方向(評価ボードからパソコン)の,図2の(b),(d)は下り方向(パソコンから評価ボード)の結果です.図2の(a),(b)はリンク幅x4,図2の(c),(d)はx8による結果です.実線が実際に得られた測定値,破線は次節で説明する理論見積もりです.図2の結果から,以下のことが読み取れます
(1) 転送するデータのサイズにかかわらず,上り方向の転送ではPIO read転送よりもDMA write転送が,下り方向ではDMA read転送よりもPIO write転送が高い性能を示しています.PIO read転送はそもそも高いスループットを期待されていない,ステータス・レジスタの読み出しなどに使用する転送方式ですから,こちらについては妥当な結果といえます.一方,DMA read転送に関しては少々意外な結果となりました.DMA転送は転送開始までのレイテンシが大きいため,データ・サイズの小さいところでの性能は期待できません.しかしデータ・サイズが大きいところでのスループットは,PIO writeを上回ってほしいところです.そうなっていないのは,基本的にはパソコンのチップセットに原因があります(詳細は後述する).
(2) PIO write転送の性能が振動しているのは,Core2プロセッサのWrite Combiningが64バイト単位で行われるためです.Write Combiningはデータ長の短い複数のwrite命令を結合し,一つのwrite命令にまとめあげる機構です.Core2の場合,64バイトごとにまとめられるため,64バイトに満たない半端なデータは転送効率が落ちます.その影響がグラフの振動として見えています.
(3) PIO write転送の場合,データ・サイズが1Kバイトもあれば,転送開始のレイテンシの影響は無視できることが分かります.DMA転送についてはデータ・サイズ10Kバイト程度まで影響が残っています.
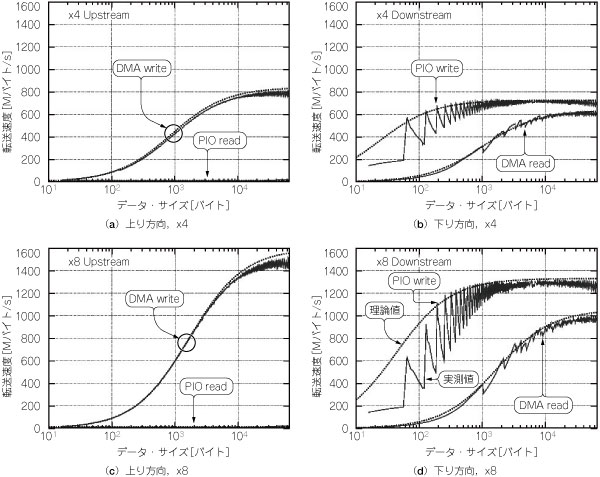
図2 評価ボードを使った転送性能測定の結果
転送するデータのサイズに対して,得られた実効性能をプロットした.下り方向はパソコンから評価ボードへの,上り方向は評価ボードからパソコンへの転送.実線は実測値,破線は論理見積もり.


