無償IPコアでよく分かるPCI ExpressのFPGA実装技術 ―― 知っておきたいIPコア実装のキモ
2.転送速度の理論見積もり
● PCI Express転送性能を定量的にモデル化する
測定で得られた転送性能は,IPコアが本来持っている能力を十分に発揮した,妥当な結果なのでしょうか.妥当でないならばチューニングによって性能を向上できるかもしれません.逆に,もしすでに妥当な性能が得られているならば,それ以上のチューニングに開発時間を割くのは無駄ということになります.
得られた性能の妥当性を検討するには,性能の理論的な上限を知ることが必要です.転送速度の理論的上限値を知ることはまた,動作検証にも役立ちます.一見正しく動作しているように見える回路でも,実効性能が理論値に達していない場合には,何らかの不具合を生じている可能性があるからです.転送エラーによってTLPの再送が頻発しているにもかかわらず,ごくまれに偶然転送が成功し,その結果通信に問題がないように見えてしまっている場合などがその例です.
PCI Expressリンクのピーク性能は,リンク幅とリビジョンが決まれば,表1のように定まります.しかしこの値はTLPのヘッダによるオーバヘッドや通信開始に要するレイテンシなどをすべて無視した場合の性能限界であり,実効性能の指標とするにはあまりに大ざっぱです.ここでは理論性能をもう少し詳細に見積もってみましょう.
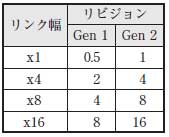
表1 ピーク性能(Gバイト/s,双方向)
実効性能が表1のピーク性能(Gバイト/s)から低下する主要な原因には,以下のものが考えられます.
(a) TLPはデータ本体だけでなく,各プロトコル層で使用されるヘッダやフッタを含んでいます(図3).従ってTLPの転送に必要なクロック・サイクル(Ctlp)は,ヘッダやフッタのオーバヘッド(Chdr)の分だけ,データ本体の転送に必要なサイクル(Cdata)よりも大きくなります.

図3 TLPの構造
(b) レジスタ・アクセスなどといったごく短いデータ転送を除くほとんどの転送は,複数のTLPに分割されます(図4).各TLPの運ぶデータのサイズ(ペイロード長)は,最大ペイロード長以下に制限されます.チップセットの設計によっては,パソコンから送出されるデータは最大ペイロード長に満たないTLPに分割されてしまう場合もあります.さらに,IPコアやユーザ回路の設計によっては,TLPとTLPの間にアイドル・サイクルが挿入される場合があります.このオーバヘッドをCidleとおきます.
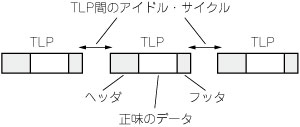
図4 PIOの転送オーバヘッド
TLPのヘッダ,フッタによるオーバヘッドと,TLP間のアイドル・サイクルからなる.
(c) DMA write転送とDMA read転送の場合にはさらに,CPUが転送要求を出してから実際に最初のTLPがリンク上に送出されるまでの間のレイテンシと,転送の終了判定にかかるオーバヘッドが加わります(図5).このオーバヘッドをCdmaw,Cdmarとおきます.PIO転送の場合にも,ごく短いながらレイテンシがあります.これをCpioとおきます.
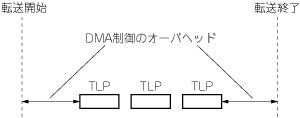
図5 DMA write転送のオーバヘッド
図4のオーバヘッドにDMA制御のオーバヘッドが加わる.
(d) DMA read転送の場合には,読み出しを要求できるサイズに上限(Max Read Request Size;最大リード要求長)が定められています.それを超えるデータ転送を行うには,データを最大リード要求長以下に分割し,転送ごとに読み出し要求を発行する必要があります(図6).読み出し要求の発行にかかるオーバヘッドをCrdreqとおきます.
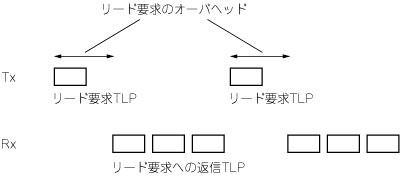
図6 DMA read転送のオーバヘッド
図5のオーバヘッドにリード要求TLPのオーバヘッドが加わる.
(e) TLPは各レーンにまたがってリンク上を流れるため,TLPの(ヘッダやフッタを含む)総バイト数がリンク幅のちょうど整数倍でない限り,一部のレーンには有効なデータを運んでいないサイクルが生じます(図7の灰色部).
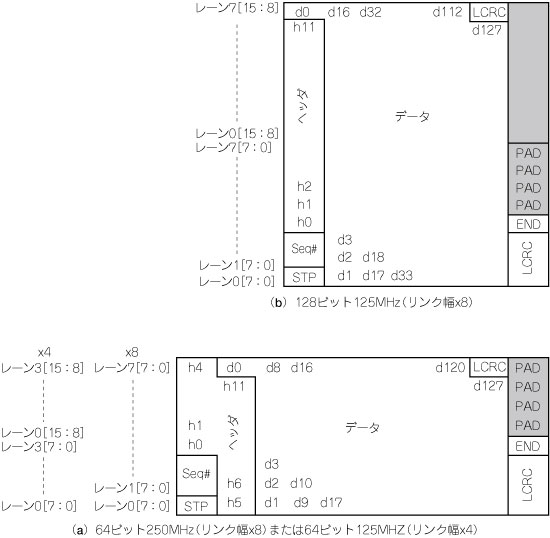
図7 複数のレーンに分割(バイト・ストライピング)されたTLP
ペイロード長128バイト,アドレス幅32ビット,ECRCなしの場合.
(f) DLLPやPLPなど,TLP以外の転送がリンクの帯域を消費します.
これらの要因のうち(f)については,影響が小さいと予想される上,定量的な見積もりが困難なので,とりあえず考慮しないことにします.それ以外すべての要因を考慮すると,ピーク性能P0に対する実効性能Pの効率は,
- PIO転送の場合
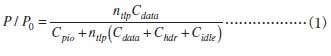
- DMA write転送の場合

- DMA read転送の場合
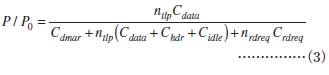
と見積もれます.ここでntlpは,1回のデータ転送に必要なTLPの個数です.またnrdreqは,1回のDMA read転送に必要な読み出し要求TLPの個数です.総データ・サイズをD,最大ペイロード長をDmplsとおけば,ntlp=D / Dmplsと表せます.また1サイクル当たりに転送できるデータ・サイズをDwidthとおけば,Cdata=Dmpls / Dwidthと表せます.同様に最大リード要求長をDmrrsとおけば,nrdreq=D / Dmrrsと表せます.
この見積もりから,定性的には次のことが分かります.
|


