無償IPコアでよく分かるPCI ExpressのFPGA実装技術 ―― 知っておきたいIPコア実装のキモ
3.Altera社非公認(!),x8サポート対象外のFPGAでx8を実現する技術
Altera社の資料によれば,Arria GXがサポートするPCI Expressインターフェースはリンク幅x4まで,ということになっています.高速トランシーバを8チャネル以上内蔵しているデバイスであっても,x8はサポートしていません.この理由をAltera社のテクニカル・サポート・サイトmySupportへ問い合わせたところ,「社内でリンク幅x8のインターフェースの実装や動作検証を行ったことがないので動作を保証できない」旨の回答を得ました.
どうやら「x8は絶対に実現不可能」というわけではないようです.頑張れば何とかなるのかもしれない,筆者らはそう考え,思いきってArria GXのx8評価ボードを開発してみました.リンク幅x8のカード・エッジにArria GXのトランシーバ8個を結線したボードです.
いざArria GX内にインターフェース回路を実装する段階になって,二つの問題が浮上しました.一つはCRC生成回路のタイミングの問題,もう一つはArria GX内蔵のトランシーバがx8 PIPEインターフェースに対応していない問題です.これらの問題の解決には相当の時間を費やしましたが,最終的には無事Arria GX上でリンク幅x8のインターフェースを動作させることに成功しました.
● 16Gbpsでデータを処理できる高速CRC回路の設計
PCI Expressの各レーンには2Gbpsのデータ入力がありますから,リンク幅x8用のCRC生成回路には16Gbpsのスループットが必要です.しかしこの値は,通常の方法ではとうてい実現できません.Altera社の提供するCRCコアを,Arria GXの上位モデルStratix II GXの最高スピード・グレード(グレード -3)で用いた場合でさえ,スループットは15Gbps程度,と資料にあります.Arria GXで16Gbpsを達成するには,CRC生成アルゴリズムに何らかの工夫が必要であることが分かります.
調査の結果,Walmaによるアルゴリズム(1)ならば16Gbpsを達成できることが判明しました.2007年にIEEEのジャーナルに掲載されたばかりのアルゴリズムです.今のところ,これが筆者の発見できた唯一の解決策です.
通常のCRC生成アルゴリズムでは,入力データを逐次的に処理します.前の入力データに対するCRCが求まるまで次の入力データの処理を始められないので,並列化は不可能に思えます.
しかしWalmaのアルゴリズムは,CRCの持つ線型性と,ある1次変換行列Hを利用して並列化を可能にします.線型性とは任意のデータAとBに対して,
CRC(A xor B)=CRC(A) xor CRC(B)
が成り立つということです.ここでCRC()はCRCを求める演算,xorは排他論理和を表します.「ある1次変換行列H」は入力データAの末尾に1ビットの0を追加したA' に対するCRCを,
CRC(A')=H・CRC(A)
によって与えるような変換です.行列Hの具体的な形はCRC算出式の簡単な変形で求められます.CRC(A)に左からHnを乗ずれば,Aの末尾に0をn個付け足した入力に対するCRCを計算できます.
Walmaのアルゴリズムではまず,入力データを複数の断片に分割し,それぞれに対するCRCを通常のアルゴリズムで計算します.各断片に対する計算は独立に行えますから,並列に実行可能です.次に,求まったそれぞれのCRCに対してHを,適切な回数乗じることで位置合わせを行います.つまりそれぞれの断片が,元データのどの部分から切り出されたものかに応じて,断片の先頭と末尾に0を付け足すのです(このとき「入力データの先頭に0をいくつ付け足してもCRCの値は変わらない」という性質も利用する).こうして得られたCRCの断片すべての排他論理和をとると,元の入力データに対するCRCが求まるというわけです.8ビット入力を4ビットの断片二つに分割してCRCを求める場合の例を図9に示します.
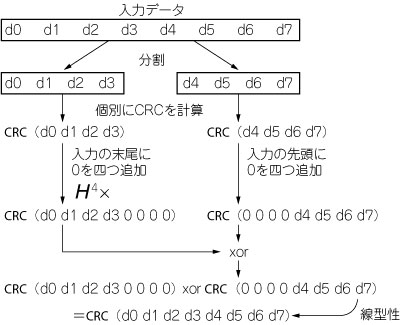
図9 並列CRC計算の例
8ビットの入力データを4ビットの断片二つに分割し,それぞれについてCRCを求める.求まったCRCに対して適切な1次変換を行ったのちに,CRCの線型性を利用して二つのCRCを合成すると,元の8ビット入力に対するCRCを求められる.
CRC計算をより高速に行うには分割を細かくして断片当たりのデータ幅を減らします.Hnの乗算を行う部分はパイプライン化できるので,この部分はパイプライン段数を増やすだけで処理速度を上げられます.
筆者の開発したコアはリンク幅x8を128ビット@125MHzのPIPE(PHY Interface for the PCI Express Architecture)で実装しています.つまり8nsのクロック・サイクルの間に128ビットのデータ入力があります.これを32ビットの断片4個に分割してCRCを求めています.Hnの乗算部分は7段のパイプラインで処理しています.これに前処理や後処理が加わり,結局CRC生成回路全体をレイテンシ10クロックのパイプライン4本で実現しています.
Walmaのアルゴリズムを用いれば,パイプライン本数を増やすことでレーン幅x8どころかx16にも対応できるはずです.ただし現在のところ回路資源の消費量がかなり大きく,パイプライン1本当たり1000個程度のALUTを必要とします.回路の大部分は1次変換(CRCの断片に左からH8,H16,H32,...,H32768を乗ずる演算)が占めています.
アルゴリズムの詳細については誌面の都合上説明を省略します.興味のある方は原論文をあたるか,Design Wave Magazine 2009年2月号(CQ出版 刊)の付属DVD-ROMに収録されたIPコアのVHDLソースを参照してください.一般的な逐次アルゴリズムによるCRC生成回路はpcrcpkg.vhdファイル内の関数calc_lfsr_serialにあります.Walmaの並列パイプラインによる回路はdatalink.vhdファイル内のエンティティcalc_lcrc_walmaにあります.
● 内蔵トランシーバをx8のPIPEに対応させる技術
Arria GXや,その上位デバイスStratix II GXの内蔵トランシーバを回路内にインスタンス化するには,Altera社の提供するIPコアalt2gxbを使用します.alt2gxbに与えるパラメータによって,その動作モード(PIPEやGIGE,Serial RapidIO)やリンク幅を設定できます.
Stratix II GXの場合にはリンク幅x8のPIPEモードを選択できますが,Arria GXの場合には選択可能なリンク幅はx4以下に限定されます.トランシーバを8チャネル以上搭載したデバイスでもx8は選択できません(無理に選択すると回路合成時にエラーで停止する).この理由についてAltera社の資料には明記されていませんが,筆者の推測を以下に述べます.
Arria GXのトランシーバは4チャネルごとにトランシーバ・ブロックという単位にまとめられています.同じブロック内のチャネルは,ブロック内共通のクロック信号に同期してデータを送出できます(各チャネル独自のクロックを用いることも可能).従って,同一ブロック内から送出される最大4チャネル分のシリアル・データは,送出時点で位相をそろえることが可能です.しかしほかのトランシーバ・ブロックから送出されるデータの位相までは保証できません(図10).これがx8をサポートできない理由ではないかと筆者は推測します.なおStratix II GXの場合には,二つのトランシーバ・ブロック間でクロックを共有する機構(Eight-lane Mode)が備わっているため,最大8チャネルの位相をそろえることが可能です.
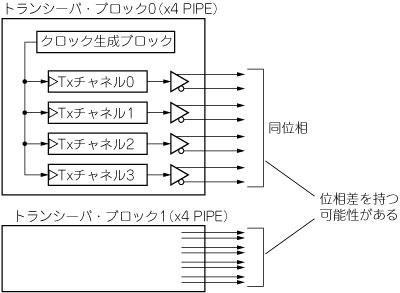
図10 x4 PIPEを2個組み合わせてx8 PIPEを作る
2組のx4 PIPE間の位相がそろうことは保証されない.通信相手デバイスの受信回路によってデスキューされることを期待する.
筆者の開発したコアでは,リンク幅x4のPIPEモードに設定したalt2gxbを2個インスタンス化し,これらを組み合わせてx8 PIPEとして使用しています.この方法では,送出されるシリアル・データ8レーンのうち同一ブロック内にある各4レーンの位相はそろいますが,2組の4レーンは互いに位相差を持っている可能性があります.これに対する対策は...何も講じていません! 送出時点での位相差は,通信相手デバイスの受信回路によってデスキューされることを期待しています.PCI Express規格ではレーン間に最大20nsまでの位相差が認められているので,実用上はこれで問題ないはずです.実際,これまでに検証した範囲内では正常に動作しています.
参考・引用*文献
(1) M. Walma "Pipelined Cyclic Redundancy Check(CRC)Calculation"Proceedings of 16th International Conference on Computer Communications and Networks,pp.365-370,2007.
かわい・あつし
(株)K&F Computing Research
川井 敦.理化学研究所,埼玉工業大学を経て2006年,福重俊幸とともにK&F Computing Researchを設立.PCI Expressをはじめとする高速インターフェース技術のコンサルティングや,ハイパフォーマンス・コンピューティング向け製品の開発を行っている.東京都最南端(母島)での,年に一度の休暇のために日々奮闘中.


