無償IPコアでよく分かるPCI ExpressのFPGA実装技術 ―― 知っておきたいIPコア実装のキモ
● 転送性能の理論値と実測値の差は5%以内
次にパソコンとの通信について,式(1)~(3)を用いた定量的な見積もりを行ってみましょう.パソコンのCPUにはIntel社のCore2 Quad(Q6600,2.4GHz),チップセットとしては同社のX38 Expressを用いることにすると,各パラメータは表2のように定まります.
表2 転送性能の見積もりに使用したパラメータ
CPUにはIntel社のCore2 Quad,チップセットにはIntel社X38 Expressを想定.筆者が実測によって求めた値を一部に含む.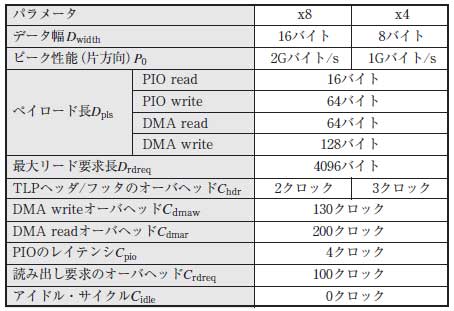
X38 Expressの最大ペイロード長は128バイトなので,DMA write転送はペイロード128バイトのTLPによって転送を行えます.一方,DMA read転送については,パソコンから送られてくるTLPを観測してみると,ペイロードは64バイトしかないことが分かります.これはおそらくチップセットの仕様による制限と考えられます.
PIO write転送は常にペイロード64バイトのTLPで行われます.これはx86系CPUにおけるWrite Combining機能の仕様による制限です.PIO read転送は,CPUが16バイト単位のリード命令しか発行できないため,常にペイロード16バイトのTLPで行われます.
最大リード要求長はPCI Expressの規格によって,4Kバイト以下に設定するよう定められています.ここでは設定可能な値のうちで最大の,4Kバイトを使用します.TLPヘッダとフッタのオーバヘッドは,図7から2ないし3クロックであることが分かります.また,筆者の実測によるとCdmaw,Cdmar,Crdreqはそれぞれ130クロック,200クロック,100クロック程度です.
Cpioは直接的な測定が困難なため,実効性能から4クロックという値を推定しました.アイドル・サイクルについては,IPコアとしてGPCIeを用いた場合には常に0です.もちろんユーザ回路側のスループットが足りずにアイドル・サイクルが挿入されることはあり得ますが,ここではそのような状況は考えません.
以上の具体的な数値を前述の式に代入すると,図2に破線で示した理論性能が得られます.ほぼ全域で,理論性能は実測性能と5%以内の精度で一致しています(表3).得られた実測値(図2の実線)は,理論限界に近い,かなり良好なものであったことが分かります.データ・サイズが大きいところで実測値が理論限界から若干落ちています(特にリンク幅x8のDMA write).これは理論見積もりでは考慮しなかった(f)の影響,つまりDLLPとPLPの転送による帯域消費の影響が見えています.
表3 IPコアGPCIeを使ったFPGAボードの実効性能
()内は理論見積もりに対する割合.最大ペイロード長128バイトの場合.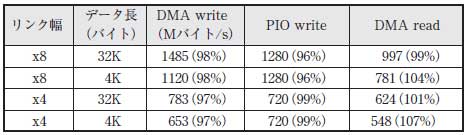
● 転送性能劣化のトラブル・シューティング
回路設計が適切であれば,実効性能は前節の理論見積もりに近い値をとるはずです(表3).見積もりではDLLPやPLPの転送を考慮していませんが,これらの転送量はTLPに比べると微小(たかだか数パーセント)です.
もし実効性能が見積もりよりも10%,あるいはそれ以上低ければ,性能低下の原因を把握しておくべきでしょう.原因はユーザ回路の設計に起因するものばかりとは限りません.パソコン側(チップセット)やIPコアの設計,あるいはそれらが複合的に関係していることもあり得ます.場合によってはパソコンのチップセットやメイン・メモリを交換するだけで性能を向上できるかもしれません.
次に症状別の事例と対処法を示します.
(1) TLPが短い
IPコアのコンフィグレーション・レジスタに設定した最大ペイロード長よりも,実際に観測されるTLPのペイロードが常に小さいという症状です.通信相手(パソコンのチップセット)がその最大ペイロード長に対応していない可能性があります.チップセットの設定を確認し,それで解決しなければ別のチップセットを搭載したマザーボードを試してみましょう.マザーボードの取扱説明書やBIOS設定はあまりあてにならない場合があります.筆者のテストしたマザーボードの中には,BIOS設定画面からは4096バイトもの巨大な最大ペイロード長を指定できるにもかかわらず,実際にはその指定は無視され,常に最小値128バイトを使用するものがありました.最終的にはトランザクションを自分の目で観測して確認することが大切です.
(2) アイドル・サイクルが定期的に入る
TLPとTLPの間にアイドル・サイクルが入る,特に転送開始直後から,各TLPの後ろに2クロックずつ,というように規則的に入る症状です.送出側でこの症状が見られるならば,ユーザ回路かIPコアのデータ送出のスループットが不足しているのかもしれません〔図8(a)〕.ユーザ回路が原因ならば送出側回路の高速化で解決できるでしょう.
IPコア内部の遅延が原因の場合には,コアの設定調整で解決できないか検討してみましょう.解決できなければ,別のIPコアに乗り換えることを検討せざるを得ません.
受信側でこの症状が見られるならば,パソコン側(チップセット)の送信端のスループットが不足しているのでしょう〔図8(b)〕.メイン・メモリの帯域不足か,あるいはチップセットの遅延によるものかもしれません.高速なメイン・メモリや別のマザーボードを試してみましょう.
(3) アイドル・サイクルが不定期的に入る
受信側でTLPとTLPの間にアイドル・サイクルが入ります.特に転送開始からしばらくは入らないのに,次第に入るようになる,という症状です.TLPの受信バッファが詰まっている場合にこのような症状が見られます〔図8(c)〕.バッファからTLPを読み出して処理する回路のスループットが足りていないか,あるいは受信バッファの空きを送出側デバイスへ通知する頻度が少なすぎるのかもしれません.前者であれば読み出し側の回路を高速化するしかありません.後者であれば,相手に通知が届くまで受信バッファが一杯にならずに持ちこたえればよいわけですから,コアのパラメータを調節して受信バッファを増やすことで解決できるかもしれません.典型的なIPコアでは,バッファの大きさは最大ペイロード長の4倍から,せいぜい8倍もあれば十分です.
送出側でこの症状が見られるならば,パソコン(チップセット)の受信端のスループットが不足しているのでしょう〔図8(d)〕.別のパソコンを試してみましょう.
(4) PIO writeが遅い
DMA readでは妥当な性能が得られており,PIO writeだけが遅い,という症状です.パソコン側から極端に短い(ペイロード長16バイト)TLPばかりが送られてくるようならばWrite Combiningが無効になっているかもしれません.パソコン上の設定(デバイス・ドライバあるいはMTRRレジスタ,PATの設定)を確認しましょう.
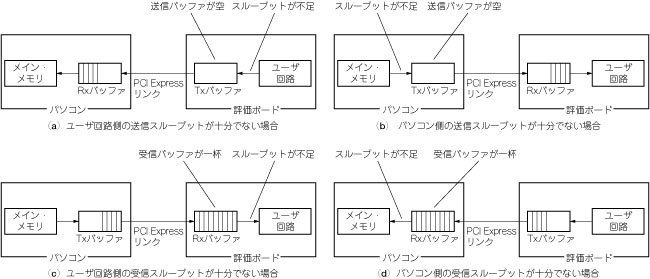
図8 通信性能を低下させる要因の例
送出側バッファへ十分な速度でデータを書き込めない場合や,受信側バッファから十分な速度でデータを読み出せない場合には,通信が一時的に中断され,実効性能が低下する.
一つのCPUが複数のデバイスに対してPIO writeを発行すると速度が低下する,という場合は単純にCPU処理がネックになっていると考えられます.転送処理をマルチスレッド化し,複数のCPUで並列実行すれば解決できるでしょう.並列化しても遅いのであれば,メイン・メモリへのアクセスに競合が起きているのかもしれません.
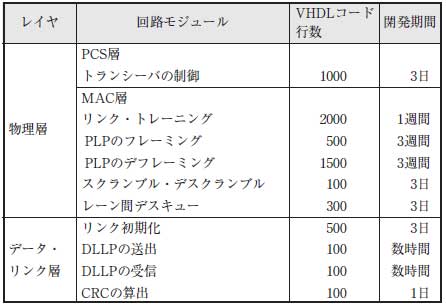
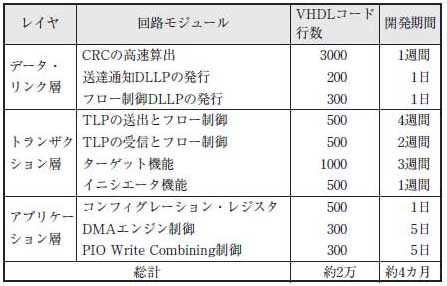
筆者が開発したPCI Express IPコア「GPCIe」の主要な回路モジュールと,その規模(VHDLコードの行数)を表Aに示します.もちろんこれらの値はあくまで大まかな目安にすぎず,開発者の技術力や開発に割くことのできる時間,やる気,体力などに大きく依存します.しかしこういった内部情報は通常,あまり公表されることはないものですし,IPコアの開発あるいは改変を検討しているエンジニアにとっては参考になるかもしれないと考え,あえて公開することにしました.
表A 主要な回路モジュールの規模
徐々に機能を追加して改良したモジュールや,後日不具合を修正したモジュールもあるため,開発期間は大まかな目安にすぎない.