CUDA技術を利用したGPUコンピューティングの実際(後編) ―― FFTを利用した光波の伝播(フレネル回折)をGPUで高速計算
● ループ・アンローリングを併用してさらに高速に
ここではループ・アンローリングという手法を用いて,Kernel2をさらに高速にしたKernel3をリスト5に示します.ループ・アンローリングとは,並列計算でよく使用される手法で,ループ処理を並列処理しやすいように展開することで高速化を図ります.
tmp += As[ty][0] * Bs[0][tx];
tmp += As[ty][1] * Bs[1][tx];
tmp += As[ty][2] * Bs[2][tx];
tmp += As[ty][3] * Bs[3][tx];
tmp += As[ty][4] * Bs[4][tx];
tmp += As[ty][5] * Bs[5][tx];
tmp += As[ty][6] * Bs[6][tx];
tmp += As[ty][7] * Bs[7][tx];
tmp += As[ty][8] * Bs[8][tx];
tmp += As[ty][9] * Bs[9][tx];
tmp += As[ty][10] * Bs[10][tx];
tmp += As[ty][11] * Bs[11][tx];
tmp += As[ty][12] * Bs[12][tx];
tmp += As[ty][13] * Bs[13][tx];
tmp += As[ty][14] * Bs[14][tx];
tmp += As[ty][15] * Bs[15][tx];
リスト5 ループ・アンローリング部分
リスト4の(6)のループ部分にループ・アンローリングを行いました.このループ部分をリスト5に差し替えます.このカーネルの実行時間は7.6msとなり,Kernel2に比べてさらなる高速化を達成できました.
● レジスタ,共有メモリ,スレッド,ブロックの関係
本稿の前編でも述べたように,マルチプロセッサ1個で最大8個のブロックを処理できます.また,マルチプロセッサはワープ(32スレッド)という単位でスレッドを実行すると述べました.1個のマルチプロセッサは最大24個のワープを処理できます.
マルチプロセッサにおいて1個のブロックしか動いていない場合,そのブロック内のスレッドが __syncthread による同期中は,全スレッドが __syncthread に到達するまでアイドル状態になってしまい,マルチプロセッサが遊んでしまいます.また,グローバル・メモリのアクセスには長い時間(レイテンシ)が必要で,このレイテンシを待っている間も,マルチプロセッサが有効活用できない可能性があります.
2個以上のブロックがマルチプロセッサに割り当てられていれば,あるブロック内のスレッドが同期中のときやグローバル・メモリのレイテンシを待っているときでも,ほかのブロックに切り替えてオーバラップ動作させることができ,マルチプロセッサを有効活用できます.
作成したカーネルが,マルチプロセッサで常に8個のブロックや24個のワープで処理されているかというと,残念ながらそうではありません.シェアード・メモリやレジスタは共有資源となっているため,ブロックが使用しているシェアード・メモリの容量や,スレッドが使用しているレジスタ数が多い場合,マルチプロセッサで実行できるブロック数やワープ数は減少します.
● ブロック数やワープ数はツールで見積もり可能
作成したカーネルで,ブロックやワープが実際どの程度動いているのかは,分かりづらいものがあります.しかし,これを見積もることができるツール「CUDA Occupancy Calculator」(本稿執筆時点ではバージョン1.2)がNVIDIA社によって用意されています(3).これを利用してみましょう.
使い方は簡単です.まず,図6の中の(1)の部分で使用しているGPUを選択します(G80かG84のどちらかが選択できるようになっている).G80はGeForce 8800などで,G84はGeForce 8600です.
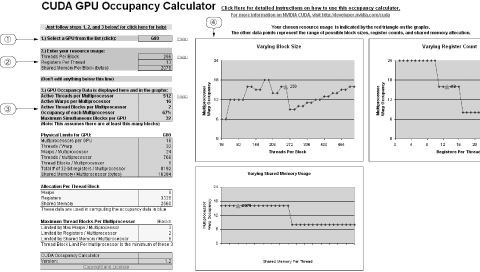
図6 CUDA Occupancy Calculator
作成したカーネルで,ブロックやワープが実際どの程度動いているのかを見積もるツール.
次に(2)の部分に,上から順に「ブロック当たりのスレッド数」,「スレッド当たりのレジスタ数」,「ブロック当たりのシェアード・メモリ数(バイト単位)」を入力します.「ブロック当たりのスレッド数」は,リスト1の(5)で設定したように256個(BLOCK×BLOCK)なので,256を入力します.
次の「スレッド当たりのレジスタ数」と「ブロック当たりのシェアード・メモリ数(バイト単位)」は,nvccコンパイラが最適化を行うためソース・コードから正確な値を見積もることが困難です.そこで,コンパイル・オプションに「-keep」オプションを追加し,再コンパイルを行うと,プロジェクトのディレクトリ内にcubinファイルが作成されます(本稿では,ファイル名がmain.cubinになっている).このファイルは,どの程度のレジスタやシェアード・メモリ,ローカル・メモリがカーネルで使用されているかを報告します.図7にcubinファイルから抜粋したKernel2のリソースの使用状況を示します.このレポートによると,ローカル・メモリ(lmem)は使用されておらず,シェアード・メモリ(smem)はブロック当たり2076バイト,レジスタ(reg)はスレッド当たり13個となっています.これらの数値を入力します.
code {
name = Kernel2
lmem = 0
smem = 2076
reg = 13
bar = 0
bincode {
~ 省略 ~
}
const {
~ 省略 ~
}
}
図7 cubinファイルによるシェアード・メモリ,レジスタの使用状況
ローカル・メモリ(lmem)は使用されておらず,シェアード・メモリ(smem)はブロック当たり2076バイト,レジスタ(reg)はスレッド当たり13個となっている.


