CUDA技術を利用したGPUコンピューティングの実際(後編) ―― FFTを利用した光波の伝播(フレネル回折)をGPUで高速計算
(2)で,開口面h_bufに矩形開口を設定します.ここでは,サイズが40×20の矩形開口を開口面(512×512)の中心(256,256)に置くことにします.ただし,FFTによるフレネル回折積分は巡回畳み込みの計算となるため,開口面のサイズを2N×2N(1024×1024)に拡張し,拡張した領域は0で埋めておきます.この矩形開口は穴が開いた単純なもので,入射光の振幅のみを変化させます.そのため,図9のマクロmake_cuComplexを使用して,開口面h_bufの実数部について,光を通過する部分を1.0,光を遮断する部分を0とします.また,入射光の位相は変化しないので,開口面h_bufの虚数部はすべて0とします.

図9 make_cuComplexの書式
引き数で指定した実数部と虚数部の数値から,cuComplex型の複素数を作成する.

図10 cufftPlan2dの書式
2次元FFT用のプランを作成する際に利用する.
(3)で,開口面のFFTを計算します.CUFFTでFFTを実行する前に,初めにプランを作成します.プランとは,何次元のFFTを行うのか,FFTを行うデータ・サイズやそのデータが複素数か実数かなどを決めるものです.CUFFTは1次元から3次元までのFFTをサポートします.ここでは2次元FFTを使用するため, 2次元FFT用のプランを作成するcufftPlan2dを使用します(図10).FFTを行うデータ・サイズは2N×2Nで,開口データが複素数であり,FFTの実行結果も複素数となるため,CUFFT_C2Cを指定します.②で作成した矩形開口データh_bufをcudaMemcpyでd_buf1へ転送します.その後,cufftExecC2CによるFFTの計算をGPUで行います(図11).順FFTはCUFFT_FORWARDを指定します.その計算結果はd_buf2へ格納します.
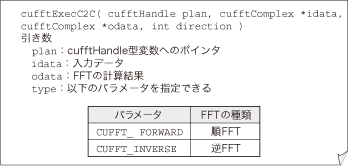
図11 cufftExecC2Cの書式
FFTの計算をGPUで行う際に利用する.
(4)でp(x,y)の算出と象限の交換(Matlabなどのfftshiftに相当)を行い,h_bufに格納します.⑤でp(x,y)のFFTを計算し,計算結果をd_buf1へ格納します.
(5)でFFT[a(x,y)](d_buf2に格納)とFFT[p(x,y)](d_buf1に格納)の乗算をGPUで行わせるため,カーネル関数KernelMult(リスト7)を起動します.フーリエ変換の結果は複素数となるので,FFT[a(x,y)]とFFT[p(x,y)]の乗算は,複素乗算になります.ヘッダ・ファイルcuComplex.hの中をのぞくと複素乗算を行うマクロcuCmulfがあるので,これを利用します.乗算結果はd_buf3へ格納します.
__global__ void KernelMult( cufftComplex* a, cufftComplex *b, cufftComplex *c, int width, int height)
{
//スレッド・ブロック番号を元にアドレス計算
int x = blockIdx.x*blockDim.x + threadIdx.x;
int y = blockIdx.y*blockDim.y + threadIdx.y;
unsigned int adr = (x+y*width);
c[adr]=cuCmulf(a[adr],b[adr]);
}
リスト7 複素乗算を行うカーネル
引き数で指定した複素数の複素乗算a×b=cを実行する.
(6)でcufftExecC2Cを用いてd_buf3の内容を逆FFTすることで,式(4)のFFT-1[FFT[a(x,y)]FFT[p(x,y)]]を計算します.cufftExecC2Cで逆FFTを行うには,CUFFT_INVERSEを指定します.この計算結果は,d_
buf1に格納します.
(7)でd_buf1の内容をホストへ返すことでフレネル回折積分の計算が完了します.
(8)では,CUFFTのプランの破棄とメモリの開放処理を行います.
最後に,ホストのCPUのみでフレネル回折を計算した場合と,リスト6のGPUで実行した場合の計算速度の比較を表3にまとめます.ホスト側のFFT計算には,FFTWライブラリを使用しました.
| 開口面サイズ(N×N) | ホストのみ(ms) | GPU(ms) |
| 256× 256 | 13.9 | 1.6 |
| 512× 512 | 54.6 | 5.7 |
| 1024× 1024 | 275.1 | 18 |
| 2048× 2048 | 1561 | 87 |
表3 計算時間の比較
* * *
CUDAをこれから始める方を対象に,CUDAのハードウェアとソフトウェアの特徴と,Windows XP上での環境構築,幾つかの例を通してCUDAを使用したプログラミング方法を紹介しました.今回は誌面の都合で紹介しきれなかったLinux環境における環境構築,シェアード・メモリのバンク・コンフリクトの問題やその解決方法,テクスチャ・メモリ,コンスタント・メモリの使用方法なども,機会があれば紹介したいと思います.本稿を執筆するにあたり,貴重なご意見をいただいた湘北短期大学 情報メディア学科の高田 直樹氏に感謝いたします.
参考・引用*文献
(1)NVIDIA;NVIDIA CUDA Compute Unified Device Architecture Programming Guide Version 1.1,2007.
(2)NVIDIA;CUDA FFT Library Version 1.1 Reference Documentation,2007.
(3)NVIDIA;CUDA ZONE - The Souece for CUDA Developer
(4)Massachusetts Institute of Technology;FFTW Home Page
しもばば・ともよし
山形大学大学院 理工学研究科 情報科学専攻 准教授
いとう・ともよし
千葉大学大学院 工学研究科 人工システム科学専攻 教授


