CUDA技術を利用したGPUコンピューティングの実際(後編) ―― FFTを利用した光波の伝播(フレネル回折)をGPUで高速計算
● グローバル・メモリに対して演算を直接行う
初めに示すカーネルは,シェアード・メモリなどを使用せずに,グローバル・メモリに格納された二つの行列データを直接計算し,その計算結果をグローバル・メモリへ書き込んでいくものです.グローバル・メモリは,シェアード・メモリと比べて低速なメモリとなっています.この方法で実装したカーネル関数Kernel1をリスト3に示します.
__global__ void Kernel1(float *A, float *B, float *C)
{
int x=blockIdx.x*blockDim.x + threadIdx.x;
int y=blockIdx.y*blockDim.y + threadIdx.y;
float tmp=0.0;
for(int k=0; k<WIDTH; k++) {
int row=k+y*WIDTH;
int col=x+k*WIDTH;
tmp+=A[row]*B[col];
}
C[x+y*WIDTH]=tmp;
}
リスト3 グローバル・メモリに対して直接演算を行うカーネル関数
カーネル関数Kernel1の前に見慣れぬ __global__ という修飾子がありますが,このキーワードが付いた関数がカーネルとなります.カーネルで計算された結果については,必ずグローバル・メモリ経由でホストとやり取りを行います.計算結果をC言語の関数のように戻り値として返すことはできないため,カーネル関数はvoid型として宣言します.ここで,__global__ 以外にも幾つか修飾子があるので表1にまとめておきます.
| 修飾子 | 内 容 |
| __global__ | カーネル関数であることを宣言. この関数はGPU上でのみ実行できる |
| __device__ | カーネル関数内で使用する関数であることを宣言. この関数はGPU上でのみ実行できる |
| __host__ | ホストで実行する関数であることを宣言.この修飾子を省略した場合も,ホスト上で実行される.ただし,__host__と__device__の両方の修飾子が付いた関数は,ホスト上でもカーネル関数内でも使うことができる |
表1 CUDAの関数へ付加できる修飾子の種類
リスト3をCPUの行列乗算(リスト2)と見比べると,3重ループが1重ループになっていることが分かります.これは,GPUの場合は,リスト2の最も内側のループ(行ベクトルと列ベクトルの乗算を行う処理)を,各スレッドで並列実行させるためです(図4).この図では分かりやすいように2スレッド分しか示していませんが,実際にはもっとたくさんのスレッドが並列実行されています.
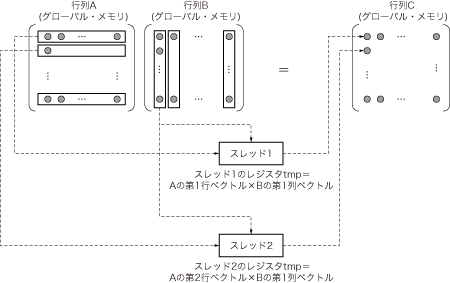
図4 Kernel1の概略
リスト3をリスト2と見比べると,3重ループが1重ループになっていることが分かる.これは,GPUの場合にリスト2の最も内側のループ(行ベクトルと列ベクトルの乗算を行う処理)を,各スレッドで並列実行させるためである.
このカーネル関数は,カーネル起動時のパラメータ設定により,ブロック数が1024個(32×32),スレッド数が256個(16×16)となり,本稿の前編で紹介したように各マルチプロセッサ,ストリーム・プロセッサで並列処理されます.
各スレッドは行列中の目的のデータにアクセスするために,blockDim,blockIdx,threadIdx(表2)の組み込み変数を使用します.uint3はCUDAにあらかじめ組み込まれた構造体です.これは,x,y,z(unsigned int型)のメンバを持ちます.
| 組み込み変数 | 機 能 |
| blockDim | dim3型.カーネル関数を呼び出す際に指定したスレッド数が格納されている |
| blockIdx | uint3型.そのカーネル(グリッド)内のブロック番号を示す |
| threadIdx | uint3型.あるブロック内のスレッド番号を示す |
表2 カーネル内で使用される組み込み変数
リスト3の変数x,yは行列内の座標を計算します.行列内の座標が決まれば,そこからこの座標に対応する行ベクトルと列ベクトルのアドレス(変数rowとcol)を算出できます.変数tmpはスレッド内のレジスタに割り当てられ,行ベクトルと列ベクトルの乗算結果を格納します.最後に,計算結果(tmp)をCへ格納することで,行列の計算を行うことができます.このカーネルの実行時間は,101 msとなり,CPUに比べて高速に計算できることが分かります.
● シェアード・メモリを使用して高速処理
ここでは,グローバル・メモリの行列データの一部をシェアード・メモリにコピーし,シェアード・メモリ内のデータに対して行列の乗算を行うカーネル関数Kernel2を用意します.シェアード・メモリを使用することで,どの程度の効果が得られるのかを示します.Kernel2の概略を図5に示します.この図では,理解しやすいようにブロックが一つだけ描かれていますが,実際には複数個のブロック(ここでは1024個)が時分割でマルチプロセッサへと割り当てられ,並列動作しています.以下では1個のブロックの動作を説明しますが,ブロックが並列動作していることを念頭において読んでください.
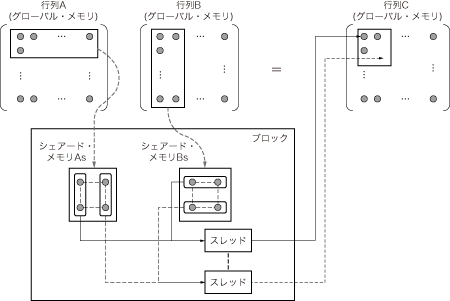
図5 Kernel2の概略
グローバル・メモリの行列データの一部をシェアード・メモリにコピーし,シェアード・メモリ内のデータに対して行列の乗算を行う.


