Cell Broadband Engineを利用したホログラム計算(前編)
2)MFC
MFCは,SPUからのチャネル命令によるリクエストや,外部メモリ,PPE,ほかのSPEからのMMIO(Memory Mapped Input Output)アクセスによるリクエストに応じて,SPU内部のローカル・ストアと,外部メモリやほかのSPUのローカル・ストアの間でDMA(Direct Memory Access)転送を行います.MFCは,チャネル・インターフェースとDMAインターフェースを介してSPUと接続されています.SPUがチャネル命令を発行すると,チャネル・インターフェースがMFCにDMAコマンドを発行する形で,DMA転送などが行われます.DMA転送時のデータは,DMAインターフェースを通じてSPUとやり取りします.
MFCの内部には16本のDMAキューが存在し,同時に最大16個のDMA転送命令を保持できます.また,SPEの外部からのDMAリクエスト用に,上記とは別の8本のDMAキューが存在します.
SPUの命令実行とDMA転送は独立して行われます.演算処理とDMA転送をうまく並列化することで,データ転送のレイテンシを隠ぺいすることが可能です.
● EIB:8サイクルの固定長パケットでデータ転送
EIBのデータ・バスは16バイトの幅を持つ4本のデータ・リングで構成されています.これは,将来,CPUコア(PPEやSPE)の数を変更するときの拡張性を考慮しているようです.EIBはCPUコアの半分の周波数で動作します.データは8サイクルの固定長パケットとして転送されます(図4).
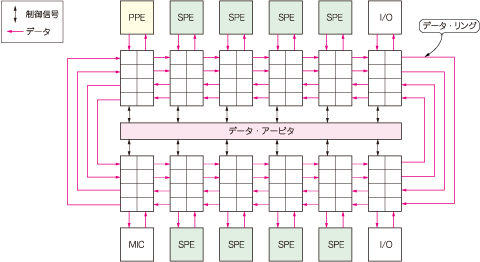
図4 EIBの内部データ・バスの構造
EIBは,PPEやSPE,外部I/Oをリング状に接続している.データは,時計回りと反時計回りに接続された2組ずつのバスのうち,論理的に近い方のリングを選択して転送される.各データ・リングは3 サイクルに1 度,アービトレーションを行い,データが衝突しなければ同じリングに複数のパケットが存在できる.これらは中央のデータ・アービタによって制御されている.
4本のデータ・リングは,2本が時計回り,残りの2本が反時計回りで接続されており,データ転送は論理的に近い方のリングで行われます.各データ・リングは,3サイクルに1度アービトレーションを行い,データが衝突しなければ同じリングに複数のパケットが存在可能です.
EIBは,250Gバイト/s以上の帯域を持ちます.この帯域を保証するために,バスに接続されたマスタ群をグループに分け,それぞれが使用できるバンド幅を割り振ります.各グループは,割り当てられたバンド幅を使い切ると一時的にメモリやI/Oを使用できなくなります.そして,ごく短い時間の後に,また割り当てられたバンド幅が利用できるようになります.このような仕組みを利用することで,優先順位の高いプロセスがより高いバンド幅を使用できるようになっています.
● 外部メモリはRambus社のXDR DRAM
メモリや外部I/Oには,Rambus社のものを採用しています.メモリ・インターフェースには,25.6Gバイト/sの帯域を持つXDR DRAMを接続しています.I/Oには,最大76.8Gバイト/sの帯域を持つFlexIOを採用しており,出力7バイトと入力5バイトを二つのチャネルに分割して転送しています.
これらのI/Oの二つのチャネルを利用して,CBEチップを4個まで接続できるようにしています.図5は,複数のCBEを利用したシステムの構成例を示しています.このように,EIBを拡張したり,クロスバ・スイッチを介して接続したシステムでは,複数のCBEチップのPPEやSPEを,一つのCBEチップの場合と同じように協調動作させることが可能です.
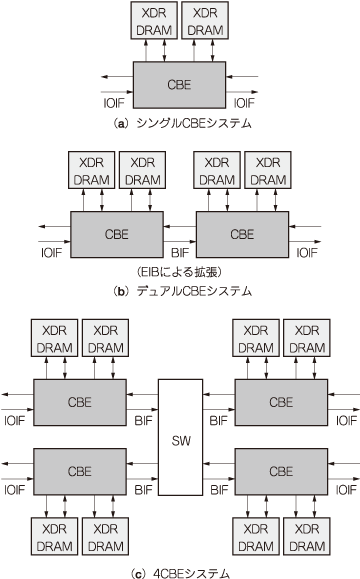
図5 複数のCBEを用いた構成例
CBEでは,使用するシステムの構成に応じてI/O チャネルの構成を変更できる.デュアルCBEシステムの場合はバス・インターフェースを,4CBEシステムの場合はクロスバ・スイッチを介することで,複数のCBEチップのPPEやSPEを,一つのCBEチップである場合と同じように,協調動作させることが可能である.
CBEの最も大きな特徴は,PPEとSPEという2種類のコアを持つその構造です.CBEは,処理機構の構造上,汎用CPUとGPU(グラフィックス・プロセッサ)の中間に位置するような仕組みを持っているといえます.


