Mali GPUコンピューティング ―― グラフィックスの枠を超えた並列計算能力の利用法
昨今のプロセッサやSoC(System on a Chip)アーキテクチャは,高い性能を効率よく引き出すため,「並列性(Parallelism)」をサポートしています.特にGPU(Graphics Processing Unit)は,膨大な並列データを処理できる優れた計算能力を備えています.最新のGPUはプログラミングに対する柔軟性が向上しており,グラフィックス描画処理以外の汎用的な処理にも利用できるようになっています.これを実現するフレームワークとして,OpenCL(Open Computing Language)やAndroid Renderscriptなどが存在します.今後,より高性能で競争力のあるモバイル機器を提供していくためには,妥協のない性能やさまざまなサポート機能を実現する必要があり,汎用計算を目的に開発されたGPUの活用に注目が集まっています.ここでは,コンピューティングにおける並列化の動向と,GPUコンピューティングに適したARM Mali-T600シリーズの第1弾となる「Mali-T604」について解説します.
●さまざまなレベルの並列性を活用して高速化
並列性は,性能と効率性を向上させる観点から,昨今のプロセッサ・アーキテクチャ設計の核となっているといっても過言ではありません.例えばスーパスカラ型CPUには,命令レベルの並列性が実装されています.SIMD(Single Instruction Multiple Data)アーキテクチャでは,ベクタ・データ演算を高速に処理できます.メモリ・レイテンシのオーバヘッドを軽減するために,同時マルチスレッディング(SMT:Simultaneous Multithreading)が利用されます.マルチコアSMP(Symmetric Multi-Processing)は,大きな性能改善をもたらします.
複数のスレッドやプログラムを並列に実行することによって,電力も節約できます.SoCの設計者は,限られた面積の中に統合化されたバス・マトリックスを共有する形で,多様なアクセラレータ・ブロックを結合します.これらはすべて,すでに確立した手法であり,性能と計算効率を引き上げることに貢献しています.
●多様なアプリに対応するコード最適化は難しい
最近のコンピューティング・プラットホームは複雑なヘテロジニアス・システムになっています.例えば,Galaxy Sllスマートフォンに搭載されているSamsung社の「Samsung Exynos 4210 SoC」は,VFP(Vector Floating Point)と128-bit NEON Advanced SIMDを備えるARM Cortex-A9(2コア),2D/3Dグラフィックス・プロセッサ Mali-400 MP(4コア),JPEG ハードウェアCODEC,マルチフォーマット対応のビデオ・ハードウェアCODEC,暗号エンジンなどが実装されています.
各プロセッサ(CPU,GPU,DSPなど)ごとに,プログラミングのアプローチは異なります.プログラム・コードを最適化するには特殊な専門知識や経験が必要であり,大概のケースでは,あるアクセラレータ向けに最適化されたコードは他のアーキテクチャへの移植が困難です.
このような背景から,プログラミング手法はプラットホームごとに,それぞれの処理能力を向上する方向へ発展しています.並列コードを記述することも容易ではなく,今日のモバイル業界では,多様なアプリケーションに対応するためのプログラムの最適化技法は,現状では理想論と捉えられているように思います.
●グラフィックス専用から汎用処理エンジンへ
従来のGPUは,OpenGL(Open Graphics Library)などのグラフィックス用の環境に対応していました.すなわちOpenGLアプリケーションを高速に処理できました.しかしこれは,見方を変えると,開発者がOpenGLのAPIによる機能に縛られることを意味しています.この問題を解消するため,「シェーダ」という小さなプログラムを利用できるように,GPU内のピクセル・プロセッサがプログラマブルになりました.複雑化するシェーダ・プログラムを扱えるようにして,徐々により汎用的かつ数学的で論理的なフロー制御演算を実行するプロセッシング・エレメントをGPUに組み込むようになりました.
●GPUコンピューティングに適したMali-T600
GPUで汎用的な計算処理能力を実現するには,ARM社のMali-T600シリーズのように,開発当初からそのような目的を意識して設計する必要があります(図1).Mali-T600シリーズはグラフィックス描画処理と汎用的な計算処理を両立できるように設計されており,ハードウェア,およびソフトウェアのドライバ・レベルで最適な相互運用を実現しています.
図1 Mali-T6xx GPUシリーズ第1弾のMali-T604(シェーダ・コアは最大4個まで拡張可能)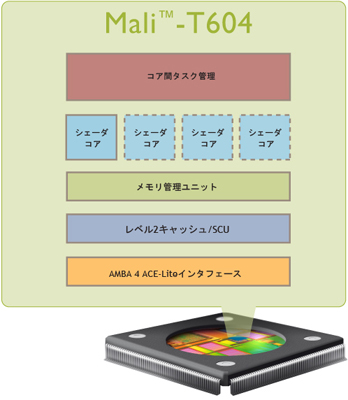
ARM Mali-T600は,キャッシュ・コヒーレント相互接続(CCI:Cache Coherent Interconnect)をサポートするAMBA(Advanced Microcontroller Bus Architecture)最新規格のVer. 4に対応しています(図2).ヘテロジニアス・コンピューティングではごく当たり前に取り扱われる「システム内のプロセッサ群によってシェアされるデータ」について,これまでのような外部メモリとの緊密な連携やキャッシュのメンテナンス処理が不要になりました.これらの処理がすべてハードウェア上で実現可能となり,ARM社が提供するドライバによって透過的に利用できます.
図2 Mali-T604,AMBA4,CCI-400を利用した構成例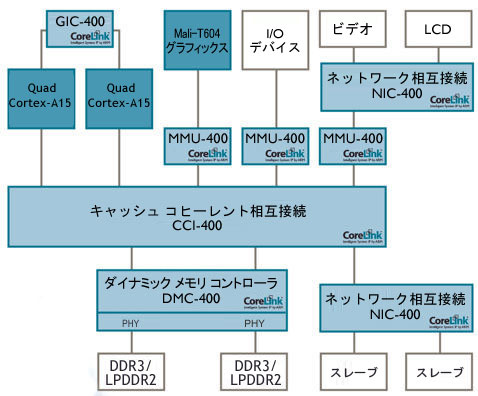
メモリ・トラフィックを減らすだけでなく,CCIは過度のデータ共有を回避します.他のマスタが本当に必要としているデータのみ,キャッシュ・ラインの粒度で転送されます.バッファやデータ構造全体をフラッシュする必要はありません.
OpenCLやRenderscriptなどのフレームワークには,サポートする精度や演算機能などの追加要件が含まれています.特に,単精度や倍精度の浮動小数点演算の要件として,IEEE 754標準に準拠することが求められています.Mali-T600は,ほとんどの演算機能(IEEE 754-2008を含む)をハードウェアとして実装しています.OpenCLの仕様で定義されている60%以上の浮動小数点演算は,Mali-T600のハードウェアにより高速に処理します.ほとんどの三角関数やべき関数,指数関数,平方根,除算などは,すべてIEEE 754規格の精度要件です.70%以上の整数演算処理も同じようにハードウェアで処理します.
Mali-T600は,64ビット整数データ型をネイティブにサポートしており,これは他のGPUにはない特徴です.バリアやアトミック操作(不可分操作)も同じようにハードウェアで処理しており,Mali-T600ではほとんどの処理が1サイクル以内(もしくは最大でも2~3サイクル以内)に完了します(図3).
図3 Mali-T604のシェーダ・コア内のアーキテクチャ(Tri-Pipe:3種類のパイプラインで構成)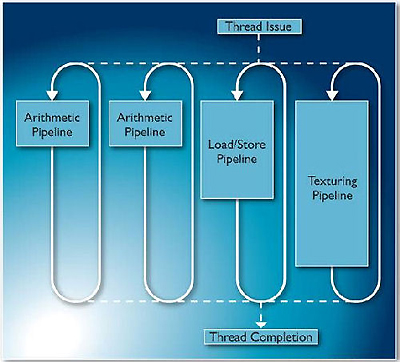
Mali-T600はこのほかに,タスク・マネージメントやイベント処理もハードウェアで最適化しています.タスク振り分けはすべて,ハードウェア・コア内にあるジョブ管理ユニットが処理します.ソフトウェア・ドライバはGPUの負荷を軽減するように作られています.例えば,すべてのスケジューリング,優先順位の設定,ランタイム同期などの処理が透過的に実行されます.
通常,GPUは,処理能力がレイテンシより重要という視点で設計されています.Mali T-600では適切なレイテンシ耐性を備えつつ,一般的なメモリ・ロード・ストアの処理を重視して設計しています.
また,ソフトウェアの開発者はさまざまなAPIを組み合わせて利用します.Maliソフトウェア・ドライバの基礎構造は,非常に効率よく最適化されています.それぞれのAPIがしっかりと結合されており,Maliソフトウェア・スタック構造の中のすべてのAPIは,同じ高位のAPIオブジェクトやアドレス空間,キュー,依存関係,イベントを共有しています.この方法により,コード・サイズをコンパクトにしつつ,性能の向上を図っています.データ構造はAPIとデバイスの間で共有されるため,不必要なメモリ・コピーが回避されます.
はまだ・たくや
英国ARM社 メディアプロセッシング部門 GPUコンピューティングマーケッティングマネージャ


