Cell Broadband Engineを利用したホログラム計算(前編)
● PPE:PowerPC上でLinuxが稼働
PPEは,64ビットPowerアーキテクチャに準拠したCPUコアです.CBEは主にOSの制御などを担い,32Kバイトの命令キャッシュと32Kバイトのデータ・キャッシュ(いずれも1次キャッシュ),および512Kバイトの2次キャッシュを持っています.現状,対応するOSはLinuxのみで,CBE用のプログラムを開発する際には専用のコンパイラやライブラリをインストールする必要があります.
PPEのプログラミングは,通常のパソコンのプログラミングと同じように行えます.ただし,CBEの性能を引き出すためには,次に述べるSPEを利用したプログラミングが必要になります.
● SPE:SIMD型プロセッサを複数搭載
SPEは主に演算処理を行うブロックで,CBEの中に複数個存在します.SPEは,演算部であるSPUとデータ転送を管理するMFC(Memory Flow Controller)から構成されています.
1)SPU
SPUは128ビットSIMD(Single Instruction/Multiple Data)型のデータ処理向けプロセッサです.
SPUは,26段のパイプライン構成を持つことで動作周波数を向上させています.このパイプラインは2系統に分かれており,それぞれ受け持つ命令が異なります.大まかには,一方のパイプラインはデータの演算処理を,もう一方のパイプラインはデータのロード・ストア命令や分岐命令を受け持ちます.アウト・オブ・オーダ発行などの処理は行いませんが,二つのパイプラインが受け持つ命令が順番に並んだ際には,2命令が同時に発行される仕組みになっています.
あるデータについて加算や乗算などのデータ処理を行うとき,通常は1命令につき一つの演算を行います.一方SIMDは,同じ命令(演算)であれば1命令でいくつかの演算を同時にこなします.同時処理できるデータの数は,パイプラインの処理幅に依存します.CBEの場合,データ幅は128ビットになっており,このデータ幅を演算するデータの間で分け合いながら処理することになります.例えば,int型やfloat型(データ幅は32ビット)の演算の場合,同じ計算であれば4データ分を同時に処理できるというわけです(図3).
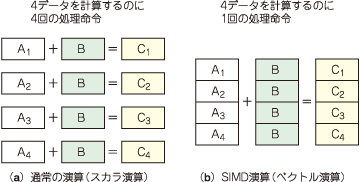
図3 SIMD演算の利点
四つの加算命令を実行する場合,通常はそれらを逐次的に4回実行することによって処理を行う.一方SIMD演算では,同じ命令であれば複数個を同時に処理できる.CBEで同じ型の変数を扱う場合は,SPEのレジスタ幅である128ビットに収まる範囲で同時に同じ処理を実行できる.
SPUは,内部にローカル・ストア(LS)と呼ばれる256Kバイトの内部メモリを持ちます.この領域にSPUで動作するプログラムの実行コードや処理するデータが置かれます.
CBEの特徴として,SPUのロード・ストア命令によってアクセスできる領域がローカル・ストアに限定されており,外部メモリに直接アクセスできないことが挙げられます.ローカル・ストアと外部メモリ,各SPUのローカル・ストア間のデータ転送は,後で述べるMFCを介して行わなければなりません.これにより,ローカル・ストアにはキャッシュ・ミスが存在せず,固定レイテンシでアクセス可能です.SPUによるデータ処理時間を正確に予想でき,それにより高速な処理が期待できます.いわば,通常のメモリの感覚で使用できるキャッシュ・メモリといったところです.
SPUは,128ビット×128本のレジスタ・ファイルを持っています.これにより,利用する演算パイプラインが深い場合やソフトウェアのループ・アンローリングを利用する場合に,高い性能を発揮するようになっています.なお,通常の汎用CPUのレジスタは,多くても数十本程度にとどまります.


