FPGAを使った数値演算回路実現の勘所(1) ―― 加算器の構成を考える
●論理合成の結果は...
結果を表3に示します.参考までに,加算器を構成するのに使用されたLUTの数も表示し,回路規模の参考値としました.では,この結果を考察してみましょう.
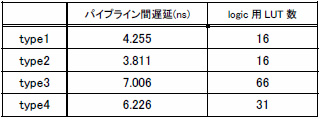
表3 論理合成による遅延と回路規模の見積もり
1) ノーマル・リプル・キャリ・アダー(type 1)の合成結果
タイミング・レポートを見ると予想通りです.最下位の入力から全けたのキャリ・チェーンを通過し,最上位の和出力までが,遅延の最長パスとして挙げられています.キャリ・チェーンの1けた当たりの遅延は0.056nsで,大変高速であることが分かります.これが大きなポイントとなります.
2) キャリ・チェーン分断型リプル・キャリ・アダー(type 2)の合成結果
type 1のノーマル・リプル・キャリ・アダーに比べて遅延が改善されていることが確認できます.最長パスは,最下位の入力から下位8けたのキャリ・チェーンを通過し,7ビット目の和出力まで,となっていました.しかし,キャリ・チェーンの長さが半分になった割には,大幅な遅延の改善は見られません.この理由は何でしょうか.図7にtype 1とtype 2の遅延の内訳をグラフ化したものを示します.
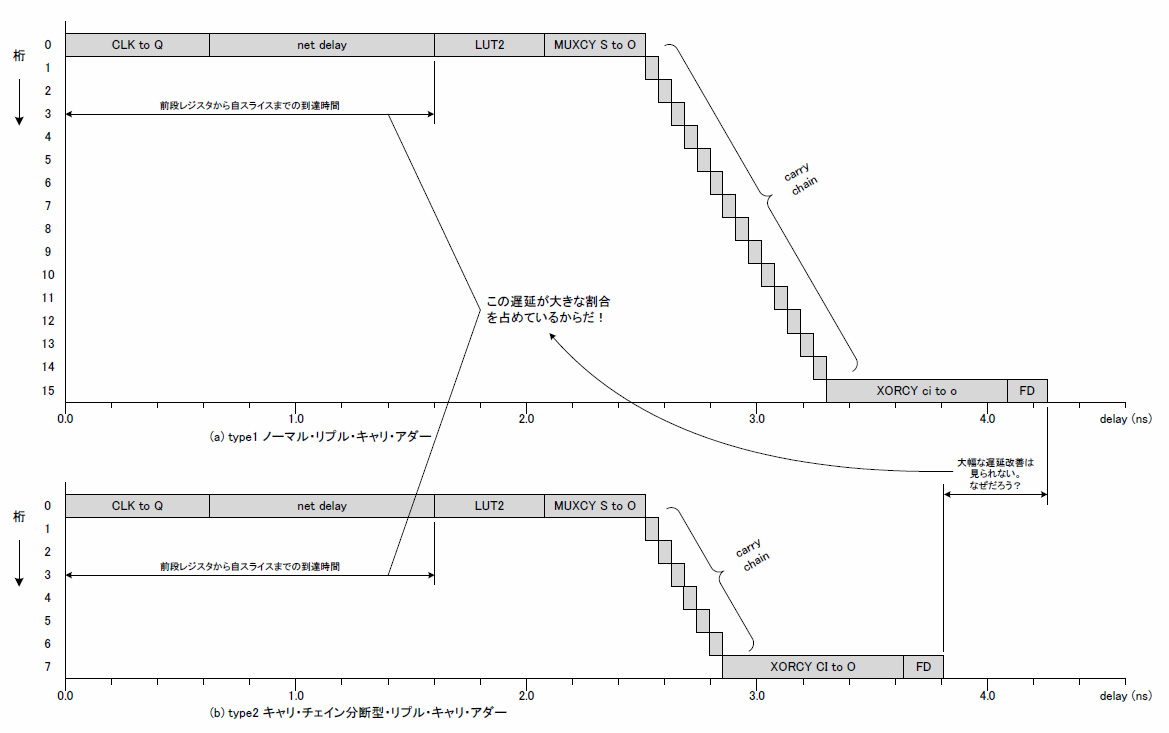
図7 type 1とtype 2の遅延の内訳
※ クリックすると拡大できます.
内訳に現れる遅延要素は以下の通りです.
- 前段レジスタのCLK to Q
- 前段レジスタがあるスライスから加算器のスライスまでの配線遅延
- 入力段ハーフ・アダーを構成するLUTのロジック遅延
- MUXCY S to O(最下位のキャリ・チェーンの入力から出力までの遅延)
- キャリ・チェーン遅延=0.056×(ビット数-2)
- XORCY CI to O(最上位XORCYの入力から出力までの遅延)
- 出力レジスタのセットアップ時間
キャリ・チェーンが8ビット分少なくなったことで短縮される遅延量は,以下のようになります.
![]() (3)
(3)
これに対して,それ以外の遅延要素,特に前段のレジスタから自スライスまでの遅延が非常に大きいようです.実はここが非常に重要なところで,スライス内やキャリ・チェーン内では専用線を使い,遅延が最小になるように構成されているのですが,スライスの外では汎用接続線を使い,大きな遅延が発生するということです.加算器を高速化するために考慮された構造からはみ出た部分では遅延が大きい,逆に言えばその構造をはみ出ないように回路を構成することが望ましい,ということになります.これが,「構造に逆らわない」ということなのです.
とはいっても,外部とのデータの出入りがない完全スタンド・アローンのハードウェアでは全く意味がないので,ここは仕方のないところです.10年以上前のFPGAであれば,ロジック・ブロック内の遅延も大きかったので,加算器を上位/下位に分断することで遅延に対する改善効果を期待できたのですが,今どきはそうもいかないようです.ただし,ぎりぎりのところでタイミング制約が満たされないような場合は,強引ではありますが,それなりの効果があるでしょう.
3) ネットワーク・アダー(type 3)の合成結果
ネットワーク・アダーは,今回試した中では最悪の遅延を与える結果となりました.その上,回路規模も最大です.遅延の内訳は,LUT5段と配線遅延になっていました.ASICなどで加算器を構成する場合は大変有用なネットワーク・アダーですが,リプル・キャリ・アダーを前提としたFPGA構造にまったくなじまないということが分かります.
「構造に逆らってはならない」という良い教訓になります.記述もAND,OR,EXORだけで機能を表現しているので,XSTにしてみれば加算器に見えないのでしょう.もっとも加算器に見えたところで,何をしてくれるかは定かではありませんが....
4) キャリ・セレクト・アダー(type 4)の合成結果
基本的には,キャリ・チェーン幅が半分になることから,type2のキャリ・チェーン分断型リプル・キャリ・アダーと非常によく似た遅延の内訳になるのですが,マルチプレクサを同一のスライス内に割り当てることができず(そのためのリソースはない),別のスライス上に割り当ててしまうことから,その分のロジック遅延と配線遅延が発生し,大幅に遅延を悪化させています.これも「構造に逆らってはならない」という良い例です.
加算のビット幅が大きい場合で,タイミング制約に滑り込みたいがレイテンシは変えたくない,といった事情がある場合は,キャリ・チェーンの遅延削減分がマルチプレクサを追加したことによる遅延の増分に勝れば,適用する価値があると言えるでしょう.
以上,なかなか面白い(あるいは予想通りの)結果となりました.結論は,「せっかくFPGAベンダが工夫してくれているのだから,ありがたくその構造に沿って使いましょう」というところですね.知ったかぶりして変な構造を押し込まないことです.
* * *
普段筆者は,FPGAの構造に逆らうようなまねはせず,ある程度の癖を理解したつもりで使っているわけですが,逆に言えば無難な使い方をしているともいえます.たまには道を踏み外してみると,また別のものが見えてきて楽しいものです.
皆さんも道草を楽しんでみてはいかがですか.
●参考文献
(1) Xilinx社;Spartan-3 ジェネレーションFPGA ユーザーガイド.
(2) Xilinx 社;Spartan-6 FPGA コンフィギャブルロジックブロックユーザーガイド.
(3) Xilinx社;Virtex-5 FPGA User Guide.
(4) Xilinx社;Virtex-6 FPGA コンフィギャブルロジックブロックユーザーガイド.
(5) Altera社;Cyclone III デバイス・ハンドブックVolume 1.
(6) Altera社;Cyclone IV Device Handbook Volume 1.
(7) Altera社;Stratix デバイス・ハンドブックVolume 1.
すずき・しょうじ


