計算能力重視のプロセッサCELLとDSPを比較する ―― アーキテクチャ,開発環境,活躍場所など
● レジスタ・セット
SPUは128ビットのレジスタを128本持っており,これで演算からアドレッシング,条件実行まで全部こなします.このレジスタはx86やPowerPCのSIMD命令と同じ考え方で利用され,一方,これら汎用プロセッサの欠点をカバーするような工夫が施されています.
SIMD演算
128ビット長のレジスタを生かし,SPUは32ビット浮動小数点数の演算を四つ並列に行います.いわゆるSIMD演算です(図5).これによってサイクル当たりの演算能力を4倍にできます.
浮動小数点演算については64ビット長の倍精度演算も用意されています.しかし,単精度浮動小数点演算のスループットが1であるの対し,倍精度浮動小数点演算のそれは数分の1に落ちてしまいます.SPUの演算能力を高い状態に維持したければ,倍精度ではなく単精度で行うようにしなければなりません.
浮動小数点数以外にも,整数型の演算用にSIMD命令が用意されています.整数型には8ビット,16ビット,32ビットがあり,それぞれサイクル当たり16,8,4の演算をこなせます.ただし,乗算命令は16×16しか用意されていません.この命令は32ビット・ワードの下位16ビットを取り出して乗算を行うものです.アセンブリ言語では使いにくく,C言語で32ビット整数乗算を行うときのパーツとして使います.文献(2)には5命令で32ビット乗算を行う例が用意されています.整数乗算が限定的にしか用意されていないことからも,SPUの演算は32ビット浮動小数点数を使うべきであることが分かります.整数はビデオ信号処理のような低ビットで高い演算能力が求められるものに使うよう考えられているようです.
4並列という小さな並列度のSIMDはx86,PowerPC,DSPで採用されて広く成功しています.この程度であればコンパイラで何とかなるケースが多くあります.
長いレイテンシ
SPUから少し離れて,x86の演算アーキテクチャであるSSEについて考えてみましょう.x86のSSEの最大の欠点は,レジスタ数が8本と少ないことです.動作周波数が1GHzを超えるようなマイクロプロセッサは長大な実行パイプラインを持っています.浮動小数点演算はこのパイプラインの中で数ステージに分割されて実行されます.その結果,実行周波数は上がっても,そのほとんどの時間はプロセッサがストールしかねないという事態になってしまいました.演算命令は,前の演算結果を参照しなければならないことが多く,その一方でレイテンシが長いため,演算命令のストールが頻発するからです.レジスタの数が8本しかなく,待っている間にほかの演算を実行できないという制限がこの問題に輪をかけています.
これを回避するために,x86のアーキテクトはアウト・オブ・オーダー実行,レジスタ・リネーミング,SMT(Simultenous Multi-threading)技術などを取り入れてきました.その結果,現在のx86プロセッサは非常に複雑な構成になっています.
SPUの演算命令も長いレイテンシを持っています(表1,表2).しかしSPUの設計者は,SMTのような複雑な機能を盛り込んでプロセッサを肥大させる代わりに,単にレジスタ数を増やしてこの問題に対処したようです.SPUは128本のレジスタを持っていますが,これはx86の16倍であり,複雑なアルゴリズムであっても十分な数のレジスタといえます.
レジスタを多く持つことで,レイテンシの大きさを吸収する最適化技法を使用できます.これはループ・アンロールとインターリーブ最適化を組み合わせる方法で,ある回の繰り返しがストールしている間を縫って,次の回の繰り返しを実行するものです(図10).レイテンシの長いプロセッサでは,命令同士の依存関係から来るストールが実行時間の大半を占めてしまいます.ループ・アンロールとインターリービングを組み合わせて使えば,演算能力を高く保ったままにできます.
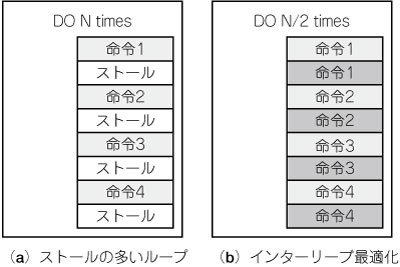
図10 インターリーブ最適化
パイプラインの深いアーキテクチャでは,命令実行に比べてストール・サイクルが多くなる.この場合,ループを展開して,隣接する繰り返しの命令を交互に実行すると,ストール・サイクルをつぶすことができる.レイテンシの大きな命令を持つアーキテクチャでは,インターリーブの深さを2ではなく,3,4と大きくしなければピーク性能を発揮させることができない.
● ループ制御
信号処理では実行回数が事前に分かる短いループが頻繁に現れるため,DSPループを高速に実行するための専用命令を持つのが当たり前になっています.これは通常DOループと呼ばれ,実行ユニットではなくプリフェッチ・ユニットで制御されます.プリフェッチ・ユニットがループ回数まで把握しているため,ループの終わりで分岐によるストールが発生しませんし,そもそもループ・ボトムに分岐命令が不要になります.
DOループは特にFIRフィルタで効いてきます.DSPはFIRフィルタを1サイクルで実行できるよう専用のMAC命令を持つのが普通です.従って,ループ・ボディが1命令ということが珍しくありません.ボディの1命令を実行するために,ループ・ボトムで分岐命令を実行したり,ループ・トップで終了条件のチェックをしたりしていては,演算時間より制御にかける時間のほうが長くなってしまいます.これがDSPにDOループが用意されている理由です.しかしSPUはDOループを持っていません.
DOループがない
DOループがないということは,短いループを実行するとオーバヘッドが耐えられないほど大きくなるということです.そのためSPUの演算効率を高めたければ,ループ・ボディを長くせざるを得ません(図11).
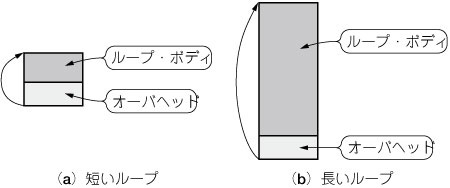
図11 ループ・オーバヘッド
ループ・オーバヘッドはループが短いほど影響が大きくなる.そのためボディが短いループについてはアンロールを施すなどしてオーバヘッドの影響を小さくする.
不幸中の幸いというべきかもしれませんが,SPUの長いレイテンシによるストールを避けるためには,ループ・アンロールと命令のインターリーブが不可欠です.そのため,ループ・ボディは必然的に長くなっていきます.結果的にDOループがないことによる制御オーバヘッドはかなり緩和されていきます.
それでも分岐によるパイプライン・フラッシュの影響は甚大です.そこでSPUは分岐による性能低下を減らすために分岐ヒント機能を実装しています.
分岐ヒント
分岐ヒントは,SPUに対してある分岐命令が「分岐をするだろう」ということを知らせるための命令です.分岐ヒントを与えない場合,SPUはその分岐命令が分岐をしないだろうと仮定して,プリフェッチを直線的に続けます.
SPUの分岐命令は,分岐するかしないかにかかわらず,分岐ヒントによる予測が当たるか外れるかで実行サイクルが決まります.分岐ヒントによる予測が当たった場合には1サイクルで実行を完了しますが,外れた場合には18から19サイクルもの時間をかけて,パイプラインのフラッシュから再フェッチをやり直します.
分岐予測の当たり外れは,特にループにおいて大きな影響を与えるため,分岐予測は非常に重要です.しかしSPUにはハードウェアによる分岐予測機構はありません.分岐ヒント命令による分岐情報を元に,分岐ターゲット・バッファと分岐命令のアドレスが管理されるだけです.従って分岐予測の精度は,純粋にプログラマに依存することになります.
性能面への影響を考えたとき,分岐ヒント命令の実行にかかるペナルティは十分小さいといえます.また,DOループ命令ではなく分岐ヒント命令を使うことによるペナルティも,SPUのループ・ボディ長がループ・アンロールによって長くなりがちであること,アプリケーションの性質としてループ回数が長くなるであろうことを考えると,たぶん無視できる程度です.
この点はアセンブリ・プログラマには負担が大きくなるのですが,SPUの設計者は妥当な性能ペナルティの範囲で設計を簡素化することを選び,プログラミングについてはコンパイラに任せるという指針を取ったようです.
分岐ヒントは統計的に偏りのない分岐に対しては無力です.そのため小さなIF文については条件分岐ではなく,プレディケーションを使うことが提案されています(図12).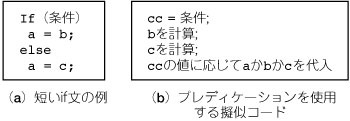
図12 プレディケーション
プレディケーションは,条件によって実行する分が異なる場合に,それぞれの場合の値を一度に計算して,後から必要な値だけ採用する方式である.短いifの場合,分岐命令によるストールの影響が大きいため,プレディケーションは絶大な効果を発揮する.SPUはプレディケーションに便利に使えるselb命令を持っている.
● ロードとストア
SPUはロード・ストア・アーキテクチャです.つまり,すべての演算はレジスタ上のデータに対して行います.メモリ・オペランドに対して演算を行うことはできません.従ってロードおよびストア命令,特にロード命令の性能はSPUの性能や使い勝手に大きく影響を及ぼします.
DSPではこの命令に対して特別な配慮がとられていることが普通です.また,信号処理の特殊性にあわせて特殊なアドレッシングが実装されていることも多くあります.
ロード命令のレイテンシ
SPUはロード命令がレイテンシを持ちます.つまり,実行後にロードしたオペランドを利用可能になるまで数サイクルかかります.これは汎用プロセッサとしては普通ですが,DSPの中にはレイテンシを持たないものがあります.
レイテンシを持たない(レイテンシ=1)利点は明白です.ロード命令の実行直後に演算を行っても,ロード命令と演算命令の間にストールが起きません.欠点はプロセッサが複雑化することです.
このレイテンシは先のループ・アンロールで帳消しにできるので,レジスタ数が多いプロセッサでは,回避することもできます.SPUはここでも命令の簡素化を優先してロード命令にレイテンシを持たせる設計になっています.
ポスト・インクリメント・アドレッシングがない
SPUの設計で筆者が解せないと感じる一番大きな点は,ポスト・インクリメント・アドレッシングがないということです.ポスト・インクリメント・アドレッシングは実装も簡単ですし,プログラムの実行サイクルが必ず減ります.また,配列や行列を用いることの多い数値演算ではポスト・インクリメント・アドレッシングを多用しますので,実装した場合の効果も大きいでしょう.
SPUのように速度重視のプロセッサで用いられないのは不思議な話です.これもハードウェアの簡素化を目的としていると思われます.
特殊アドレッシングがない
DSPと名のつくプロセッサは大抵,ビット・リバーサル・アドレッシングとサーキュラ・アドレッシングを用意しています.
ビット・リバーサル・アドレッシングは,FFTで用いられるアドレス方法です.FFTアルゴリズムはその性質上,演算後のデータが複雑にばらまかれた状態になります.このばらまき方は一見ランダムですが,よく見てみると配列のインデックス値を2進表記して,上下逆に並べ直した順になっています.
このデータの並べ直しをソフトウェアで行うと時間がかかるため,DSPはハードウェアでビット並べ替えを行う演算,あるいはアドレッシングを持っています.SPUはこれも持っていません.SPUは初期のDSPと比べて十分高速なので,ベンチマーク的な目的でFFTでしか扱わない機能を実装する必要はないという発想なのでしょう.この辺はDSPよりもRISC的です.
サーキュラ・アドレッシングもコンパクトなDSPでは当たり前に実装されています.これはサーキュラ・バッファに対するアクセスを行うための機能です.サーキュラ・バッファは,アクセスがバッファ端にないか,必ずチェックする必要があるため,ループの中にIF文がたくさん出てきます.特にFIRフィルタの実装においても,状態変数がサーキュラ・バッファであるため,この機能が必須になっていました.状態変数を内蔵するFIRフィルタ・プログラムは,1サンプルごとにデータが入力される場合に特に便利です.
SPUは初期のDSPと異なり,対象となるデータを大量にLSに置くことができます.この場合,状態変数を使わずに直接FIRフィルタ・アルゴリズムを実装できるため,サーキュラ・バッファの重要度は小型のDSPほどではありません.
サーキュラ・アドレッシングはSIMDとの相性がそれほど良くないため,これを省いたのは合理的です.


