計算能力重視のプロセッサCELLとDSPを比較する ―― アーキテクチャ,開発環境,活躍場所など
4.SPEのアーキテクチャ
CBEの性能を引き出すには,SPE/SPUを使いこなさなければなりません.この記事ではそのため個々の機能や性能を見ていきます.まず,SPEがどのようなものであるかについて説明します.
● SPEの概要
CBEのSPEの概要を図3に示します.CBEは8基のSPEを搭載しており,それぞれのSPEは1個のSPUと1個のLS(Local Store)を持っています.SPUがアクセスできるのはSPE内部の資源だけです.つまりSPUがアクセスできるメモリはLSだけです.LSに入りきれないデータやプログラムは,MFC(Memory Flow Controller)を使ってPPEから送り込まなければなりません.
MFCはDMA(Direct Memory Access)によりSPEのLSとグローバル・メモリの間でデータのやり取りを行います.各SPEのLSはグローバル・メモリ空間に固有のイメージ・アドレスを持っており,そのアドレスを介することによってSPE間のデータ転送を行うこともできます.
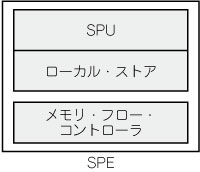
図3 SPEの内部ブロック
SPEはSPUとLS,MFCを持っている.CBEには8基のSPEが実装されている.それぞれのSPEはMFCを通じて外部メモリにアクセスできるが,SPE内部のプロセッサであるSPUがアクセスできるのはLS上の資源だけ.
● SPUコア
SPUコアはCBEのSPEの中核をなす要素で,LS上の命令を実行し,高速な数値計算を行うCPUです.このコアは大量の数値演算を短時間に終わらせることだけを目的に設計されており,そのための工夫が随所に施されています.
演算はすべて汎用レジスタ(GPR:General Purpose Registers)の上で行います.汎用レジスタは128ビット幅のものが128本用意されており,GPR0からGPR127までの名前がついています(図4).それぞれのレジスタには演算オペランドがパック形式で格納されます.つまり,浮動小数点演算を行うときには四つの32ビット浮動小数点オペランドが,16ビット整数演算を行うときには8つの16ビット整数オペランドがパックされており,これらを1命令で1度に計算オペランドとして使います.つまりSPUの演算はSIMD演算が基本になります(図5).
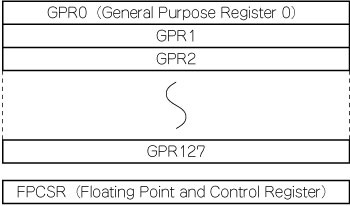
図4 SPUのレジスタ構成
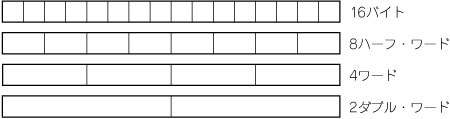
図5 パック形式のデータ
オペランドをレジスタに持ってくるためのロード命令は,オペランド・アドレスをレジスタで指定します.このとき128ビットあるレジスタの32ビットだけを使ってオペランド・アドレスを指定します.このように,非パッキング形式のデータはレジスタを一部だけ使うのがSPUの流儀です.残りの部分がもったいなく感じますが,命令セットやSPUハードウェアがいたずらに複雑になるのを嫌ったのでしょう.
CBEのSPUコアは命令実行パイプラインを2本持っています.これをうまく利用するとピークで2命令を同時に実行できます.
命令セットに特徴的なことは,制御命令やビット処理命令のような演算以外の命令が貧弱になっていることです.これらはSPUの簡略化に寄与していると思われますが,プログラミングの敷居はそれなりに高くなります.
● ローカル・ストア
CBEのLSはSPEごとに256Kバイトが用意されています.256KバイトのLSは広帯域のバスでSPEのMFCおよびSPUと接続しています.既に述べたようにSPUの汎用レジスタは128ビットの幅があり,LSはこのレジスタへのロード,およびレジスタからのストアを1サイクルのスループットで行うことができます.言い換えると16バイトのデータを1サイクルで転送できます.
一方,命令フェッチについては1サイクル当たり128バイトのデータを転送できます.128ビットの間違いではありません.命令フェッチにこれほど大きなバンド幅を与えているのは,データ転送とのバンド幅の奪い合いを最小にするよう考えてのことでしょう.また,次に紹介するMFCに対しても1サイクルで128バイトのデータ転送を許しています.
● MFC
MFC(Memory Flow Controller)はSPEとPPEのメモリ空間のブリッジとして働きます.SPE内部のSPUはSPE上のLSにしかアクセスできません.従って,より大きなメモリのアクセス,チップ外部とのやり取りはMFCを使って行うことになります(図6).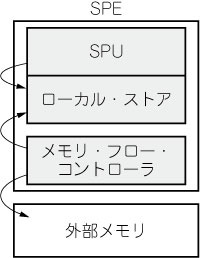
図6 MFCによるデータ転送
SPUはLS内部の資源しかアクセスできない.そのためLSにデータやプログラムを持ってきて処理のお膳立てをするのはMFCの仕事になる.データ転送ためのDMAはSPEからもPPEからも行える.
MFCはひと言で表せば強力なDMAコントローラです.CBEはMFCを使ってSPEにSPUのプログラムをロードし,データを送り込んで処理を行った後,MFCを使ってデータをSPEから取り出します.あとで述べることですが,CBEAを貫いているのは「高性能でもプログラムの生産性は落とさない」という発想です.そのためMFCのプログラミングについては細かいチューニングを行うよりも,あらかじめ決まっているフレームワーク(あるいはデザイン・パターン)に従うことを良しとしているようです.この記事ではMFCについては深く掘り下げません.
● シーケンサのように見える
SPUはプロセッサというよりは演算シーケンサに見えます.このプロセッサは,
- 高い演算性能
- C言語による高効率開発
- 汎用性
の順に優先して設計されたようで,その結果ビット・フィールド操作命令がないといったDSPらしからぬ特徴を持ちます.ビット・フィールド操作命令がないため,データ圧縮,伸長に不可欠なビット・ストリームの組み立て,分解が著しく非効率になります.こういった操作はPPEで行った方が良いという判断でしょう.
このように簡略化されている一方で,レジスタ間の演算モデルはx86のSSEやPowerPCのVMXで見慣れたものであり,かつそれらの欠点を補うような設計がされています.こういったことから考えると,設計者はSPUをシーケンサのように単純な作りにしながら,Cコンパイラによるプログラミングを許すような方向を考えたのではないかと思います.


