計算能力重視のプロセッサCELLとDSPを比較する ―― アーキテクチャ,開発環境,活躍場所など
5. SPUのアーキテクチャをDSPと比較する
以下では,SPUのアーキテクチャに少し踏み込んで,同じく演算能力指向の強いDSPと比較していきます.また,市場でDSPとぶつかっているFPGA(Field Programmable Gate Array)について少し触れていきます.
SPUと同様,演算能力の高いプロセッサとしてGPUが挙げられます.GPUを使ったCUDAプログラミング環境については,文献(7)に紹介があるので比較してみることをお勧めします.
● ローカル・ストア
LSはSPUがアクセスできる唯一のメモリです.SPUはキャッシュを持っておらず,非常に高速に動作するよう造られています.レイテンシについては後で説明しますが,スループットについては,1サイクルで1回のロードが完了するよう設計されています.
シングル・ポート
SPUは256KバイトのLSを持っています.このLSはシングル・ポートであり,命令フェッチ,データ・アクセス,MFCアクセスを同時に行えません(図7).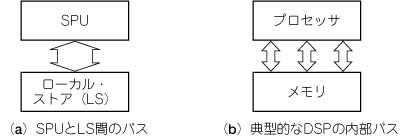
図7 SPUとLSの接続
DSPではプロセッサと内部のメモリとの間を複数のバスで接続してクロック・サイクル当たりの命令実行効率を高める.デュアル・ロードが可能である.SPUはLSとの間を1本の太いバスで接続している.命令フェッチやDMAによる干渉は少ないが,デュアル・ロードができない.
命令フェッチとMFCアクセスは128バイトを一度に読み書きできます.そのためデータ・アクセスとの衝突の頻度は,比較的小さく抑えられています.しかしデータについてはデュアル・アクセスができません.それだけではなく複数レジスタの一括読み書きもできません.
このようなシングル・ポート設計は,動作周波数が上がる代わりに,信号処理時のサイクル当たりの命令実行効率が下がってしまいます.LSは動作周波数優先で設計されているように思えます.
デュアル・アクセスがないことによるボトルネック
メモリ・ボトルネックはノイマン式コンピュータの急所であり,通常DSP設計者はこれを緩和するためにあらゆる手を尽くします.これには理由があります.多くの信号処理アプリケーションではFIRフィルタを使用します.このフィルタは1回の積和演算ごとに二つのオペランドを必要とします.そのため積和演算を1サイクルで完了できるアーキテクチャでは,1サイクルで二つのオペランドの読み込みが必要になります.これは非常に厳しい要求です.
初期のDSPでは複数のメモリ空間を搭載してデュアル・アクセスを可能にしていました.最近のDSPでは複数のメモリ・ブロックを単一メモリ空間に配置して,疑似マルチポートにするのが一般的です.この方法ではメモリの配置を工夫すればデュアル・ポートに近い性能を出せます.
SPUのLSにデュアル・アクセスがないということは,何も考えずにプログラムを組むと1サイクルごとに積和演算を実行できないということになります.
● 実行パイプライン
CBEAは実行パイプラインをどのように実装するか規定していません.そのため文献(1)だけ読んでも自分が組んだプログラムがどのように実行されるのか想像できません.SPUパイプラインの実装はCBEのプログラミング・ハンドブック(5)を読むことで,初めて理解できます.ぱっと見た感じ,CBEのSPUは2並列のスーパ・スケーラ・アーキテクチャに見えます.しかし子細に眺めると,このプロセッサは2スロットのVLIW(Very Long Instruction Word)と理解した方がよいようです.
パイプラインの概要
SPUは2本の実行パイプラインを持っています(図8).パイプラインにはevenおよびoddという名前がついており,それぞれ主に演算,主に制御命令を実行します.どの命令がどちらのパイプで実行されるかは,初めから決まっています(表1,表2).また,どちらのパイプでも実行可能な命令というものはCBEのSPUにはありません.
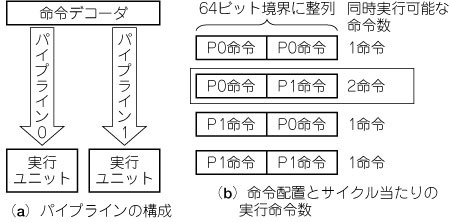
図8 SPUの実行パイプライン
SPU命令は二つあるパイプラインのどちらかで実行されるかが,あらかじめ決まっている.この図ではP0,P1と表記している.命令デコーダは命令の属性ごとに適切なパイプラインに振り分ける.同時実行の条件は64ビット境界内での命令配置に強く依存しており,スーパ・スケーラよりもVLIW的になっている.
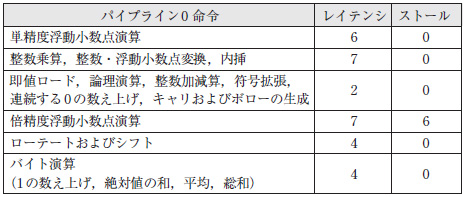
表1 パイプライン0命令のレイテンシとストール・サイクル
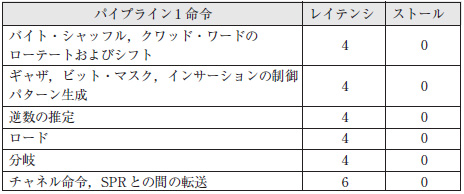
表2 パイプライン1命令のレイテンシとストール・サイクル
それぞれのパイプラインはインターロックされています.これは重要なことです.
インターロックとは,ある命令がレジスタに値を書き込もうとしている場合,続く命令がそのレジスタの値を読む準備が整うまでストールが発生して待たされることです.インターロックはx86のような高機能CPUでは当たり前の機能です.あって当然のようにも思えますが,世の中にはTexas Instruments社のTMS32C6xシリーズのようにインターロックのないプロセッサもあります.インターロックのないアーキテクチャでは,命令がその実行を終えるまでのレイテンシをプログラマが管理しなければなりません.これは普通人間の手には負えませんので何らかの専用ツールが必要です.
また,パイプラインはイン・オーダに実行されます.つまり命令の依存関係を解析して実行できるものから実行する,といった気のきいた機能はSPUには実装されていません.
実行パイプラインが2本あるため,SPUは最大2命令を同時に実行できます.
デュアル実行のための条件
SPUに最大2命令を実行させるにはどうすればよいでしょうか.x86のような高機能スーパ・スケーラ・プロセッサでは,プログラマは何もしなくても構いません.強力なデコーダ・ユニットと,それに続く実行ユニットが依存関係を解析して,最適に近い組み合わせで同時実行可能な命令を見つけ出します.
SPUはイン・オーダ実行しかしません.また,同時実行の見つけ出し機能も非常に貧弱です.むしろ,同時実行の見つけ出し機能はないといった方がよいでしょう.CBEのSPUは図8(b)に示すような特殊な配置になっている場合に限り,2命令を同時実行します.これ以外の配置の場合,命令は単に1サイクルあたり1命令が実行されるだけです.
この条件はとても厳しいものです.スーパ・スケーラではなく,VLIW的だと筆者が考える理由がここにあります.同時実行のための命令の配置が決まっているというのは,まさにVLIWの特徴です.
同時実行を行うための条件がスーパ・スケーラのように柔軟ではないとすると,プログラミングが複雑になりそうです.これはある面では正しく,ある面では間違っています.Cコンパイラにすべてを任せてしまおうと思っている人には面白くない話でしょう.しかしボトルネックをアセンブリ言語に書き下すことに慣れたDSPのエキスパートなら,飼いならしやすいと思うでしょう.VLIWは命令の実行が決定論的なので,意外にも人間がスケジューリングしやすいのです(図9).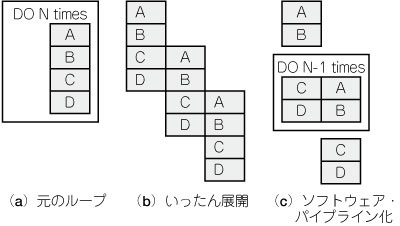
図9 ソフトウェア・パイプライン
ソフトウェア・パイプライン化を行うと,プロセッサの複数命令同時実行機能を活用できる.文献(10)に詳しい説明がある.
DSPの多くがVLIW的なアーキテクチャに進んでいった理由の一つがこれです.汎用プロセッサとことなり,DSPでは高速化したい算術アルゴリズムがある程度限られています.そのような場合,命令スケジューリングが決定論的であると,コンパイラや人間がチューニングをかけやすくなります.スーパ・スケーラが実用化される前から高性能が要求されたDSPでは,固定的な複数命令の同時実行がごく普通に行われていました.
SPUがそういったことを狙ってこのアーキテクチャにしたのか,あるいは単にデコーダをシンプルにしたかったのかは分かりません.なんにせよ,この点はDSPと同じアプローチで最適化をかけることができます.


