新人技術者のためのロジカル・シンキング入門(8) ―― CPUの演算量をひたすら削る
【3】コンパイル結果の無駄の見抜き方(2/2)
● ループの外に命令を追い出す
コンパイル結果の無駄を見抜く方法の二つ目は,「ループの中に注目する」ということです(図8).ループの中の処理は,ループの中の演算量にループ回数を掛け算したものが全体の処理量となります.そのため,ループの中の処理は削減効果が高いので,どのようなアーキテクチャのCPUを用いて実装する場合でも,ループの中の処理をいかにして減らすかというのが,最適化に当たっては常にポイントとなります(図9).
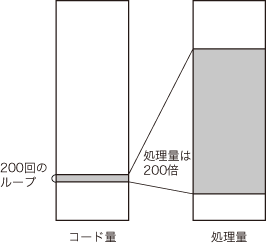
図8 ループの中は削減効果が高い
ループ中の演算が20サイクルあったとする.ループ回数が200回なら,その部分の処理量は20×200=4000サイクルとなる.ループ中の処理は削減効果が高いので,最適化する際にはまず,ループの中に注目する.
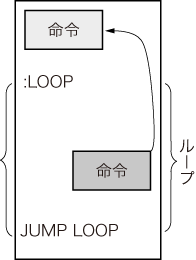
図9 ループの中に注目
コンパイル結果の無駄を見抜くには,ループ中の無駄な命令をループの外にいかにして追い出すかに注目するとよい.ループの外でも実装できる命令は,なるべく外に追い出すこと.具体例を図10,図11に挙げた.
ループの中の処理を工夫によって減らせるものとしては,例えば,テーブルのアドレス計算などがあります.テーブルのようにデータが隣り合わせになっている場合,データをループの中で次々にLOADする場合は,
- 先頭アドレスのLOAD
- オフセットの計算
- 先頭アドレス+オフセットの加算
- (3)で求めたアドレスからレジスタへLOAD
という一連の処理を行うことになります.
コンパイル結果を眺めたとき,これらがすべてループの中で行われていたとしたら,最適化の余地ありといえます(図10).これを最適化した具体例を図11に示します.LOAD対象のデータが隣り合っている事実に着目することによって,最適化のヒントが得られます.図10の(3)で求める先頭アドレス+オフセットという値は,LOADの度に1ずつ増えていくだけです.それならば,このアドレス値をループの外でレジスタに格納しておいて,ループの中でインクリメントしていけばよい,ということになるでしょう.
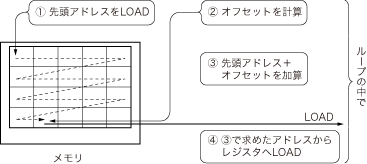
図10 最適化前のアドレス計算
テーブルのように隣り合わせのデータをループの中で次々とLOADする場合,①~④の処理を順にこなすことになる.これらがすべてループの中にあったら非効率的である.いかにして最適化するか?
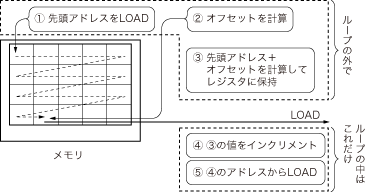
図11 最適化後のアドレス計算
隣り合わせのデータを順にLOADするなら,オフセット値は一つずつインクリメント(増分)すれば求められることになる.ここに注目して,(1)~(2)のように命令を書き換える.図10と比較すると,ループ中の命令は四つから二つに削減される.
図10と図11を見比べてみてください.この工夫で,ループの中の命令が四つから二つに減りました.


