新人技術者のためのロジカル・シンキング入門(8) ―― CPUの演算量をひたすら削る
【3】コンパイル結果の無駄の見抜き方(1/2)
では次に,コンパイル結果の無駄を見抜くコツについて考えます.
アセンブリ言語による最適化実装というのは,当然のことながら個々のCPUのアーキテクチャに依存したものとなります.そのため,個々の最適化技術は専門技術性が高く,一般論を述べるには難しい面があります.
しかし,「コンパイラがコンパイルした結果を流用する」という前提に立てば,その無駄を省いて最適化を図る際には,個々のCPUのアーキテクチャに依存しない一定のコツが存在します.
コンパイル結果の無駄を見抜く方法というのは,ある個所に注目すれば実は意外とシンプルなものなのです.それは,
- 余計なLOAD/STORE命令を省く
- ループの外に命令を追い出す
というものです.順に解説していくことにしましょう.
● 余計なLOAD/STORE命令を省く
アセンブリ言語のような低級言語とC言語のような高級言語について,コーディングに対する考え方の違いを挙げればきりがないでしょう.しかし,最適化する際にポイントとなるのは,「アセンブリ言語はメモリからレジスタにデータを移動させないと演算できない」という点です(図6).
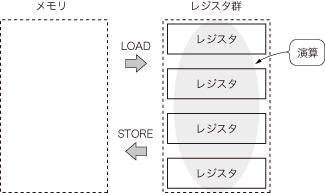
図6 アセンブリ言語は演算の前後にLOAD/STOREが必要
アセンブリ言語は高級言語と違って,メモリとレジスタ間でのデータの移動を意識しないとコーディングできない.データはメモリ上に存在するのに対して,演算はレジスタ上で行うからである.
データはメモリに格納されているのに対して,アセンブリ言語の演算命令はレジスタ上で行います.メモリからレジスタにデータを移動させることをLOAD,逆にレジスタからメモリにデータを移動させることをSTOREと呼びます.アセンブリ言語のコーディングでは,必ずこのLOADとSTOREを演算の前後で行っています注3.従って,コンパイル結果の無駄を見抜く一つ目のポイントは,このLOAD/STOREに無駄がないかどうかに着目することです(図7).
注3;命令体系によってはLOADとSTOREをともにMOVE命令で記述する場合もある.コーディングの際に用いるニーモニック(疑似命令)の呼び方は個々のCPUによって異なるので注意していただきたい.
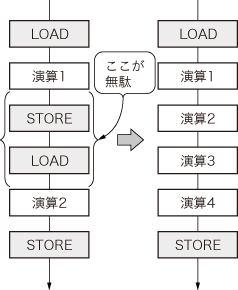
図7 演算の前後のLOAD/STOREに着目
レジスタ上で演算を続けられるのであれば,メモリ-レジスタ間のデータの移動は無駄である.従って,演算の前後にLOAD/STOREが繰り返されていれば,最初と最後に1回ずつLOAD/STOREにまとめればすむことになる.
● レジスタの有効活用が最適化のポイント
ここで,「レジスタの数には上限があるから,どんな場合でもLOAD/STOREが省けるわけではないはずだ」と気付いた方がいるかもしれませんが,全くその通りです.アセンブリ言語レベルでの最適化というのは,「CPUのレジスタをいかに無駄なく活用するか」ということの裏返しでもあるのです.
メモリ-レジスタ間のデータの移動を削減して演算を行えば,演算の途中結果などはすべてレジスタに保持しておかねばならないことになります.CPUが持っているレジスタの数には上限があるため,レジスタの数があふれてしまえば,それ以上はLOAD/STOREが削減できず,メモリ・アクセスが必要ということになります.従って,数に限りのあるレジスタをうまく使い回して余計なLOAD/STOREを演算の間に挟まずにコーディングすることが,アセンブリ言語レベルでの最適化のコツです.
余計なLOAD/STORE命令を削減することは,とりもなおさず,CPUに用意されているレジスタを無駄なく使うことにつながる,ということに注意してください.


