CUDA技術を利用したGPUコンピューティングの実際(前編) ―― グラフィックス分野で磨かれた並列処理技術を汎用数値計算に応用
また,ブロックはさらに細かい粒度の「スレッド」という単位に分割されます.このスレッドと配列の各要素が1対1に対応して,各要素を並列に計算(A[ ]+1)します.
2)スレッドへの分割
スレッドは,ストリーム・プロセッサにより処理されます(図5).一つのマルチプロセッサは8個のストリーム・プロセッサを持つため,一つのマルチプロセッサで物理的に並列処理できるスレッド数も8個となります.一般に,ブロック当たりのスレッド数は,マルチプロセッサ当たりのストリーム・プロセッサ数よりも多いため,時分割でスレッドを割り当てることになります.
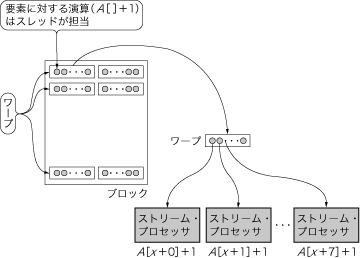
図5 ブロックのスレッドへの分割
スレッドは,ストリーム・プロセッサによって処理される.一つのマルチプロセッサは8個のストリーム・プロセッサを持つため,一つのマルチプロセッサで物理的に並列処理できるスレッド数も8個となる.一般に,ブロック当たりのスレッド数は,マルチプロセッサ当たりのストリーム・プロセッサ数よりも多いため,時分割でスレッドを割り当てることになる.
ブロックをスレッドに分割する際,適当に分割するわけではなく,32スレッドを一固まりとした「ワープ」と呼ばれる単位に分割します.このワープは4クロックかけて8個のストリーム・プロセッサで処理されます.スレッド・スケジューラは,複数あるワープを,実行できるものから次々にストリーム・プロセッサへ割り当てていきます(アウト・オブ・オーダ実行).
このように,スレッドはばらばらに並列実行されます.しかし,スレッドがある処理(計算)を完了するまで,次の処理に進みたくない場合があります.これは,正しい計算結果が確定しない状態で次の処理に進んでしまい,つじつまが合わなくなる可能性を回避するためです.CUDAではこのような事態を避けるために,すべてのスレッドがプログラミングで設定した同期ポイントに到達するまで,処理を待たせることができます(並列処理の世界では,このような同期化手法をバリア同期と呼ぶ).
マルチプロセッサの中の各ストリーム・プロセッサは,クロック・サイクルごとに同一の命令(この例では,クロックごとに配列からデータを読み出す命令,そのデータに1を加算する命令,計算結果を配列に書き戻す命令)が実行され,異なるデータ(図5のA[x+0]~A[x+7])を処理するSIMD型プロセッサとして動作します.以上が,GPUがカーネルを実行する流れとなります.
3)ブロック番号とスレッド番号を使ったアドレス算出
今回の例では,スレッドは配列データの要素に1対1に対応しています.スレッドがどのようにして配列Aからデータを取得するのかを見てみます(図6).各ブロック,スレッドには固有のブロック番号とスレッド番号が割り当てられています.スレッドは,これらの番号を利用して,配列からそのスレッドに対応するデータが格納されているアドレスを算出することができます.
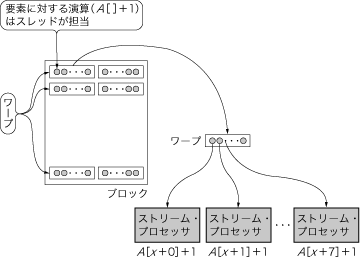
図6 ブロック番号とスレッド番号
各ブロック,各スレッドには固有のブロック番号とスレッド番号が割り当てられている.スレッドは,これらの番号を利用して,配列からそのスレッドに対応するデータが格納されているアドレスを算出する.


