CUDA技術を利用したGPUコンピューティングの実際(前編) ―― グラフィックス分野で磨かれた並列処理技術を汎用数値計算に応用
2.CUDAとは
CUDAを用いてGPUを制御する場合,GPUを装備したコンピュータは,GPUを制御するという意味で「ホスト・コンピュータ」(以下,ホスト)と呼ばれます.GPUは,ホスト側から見ると高性能なコプロセッサとして扱うことができます.
● プロセッサが1クロックで積和演算を実行
CUDA対応GPUのハードウェア構成を図2に示します.「マルチプロセッサ」と呼ばれる回路ブロックが複数並んだ構成になっています.一つのマルチプロセッサの中には,「ストリーム・プロセッサ」〔参考文献(1)ではこのプロセッサを「Processor」と呼んでいる.また,前節では「統合シェーダ」と呼んだ.便宜上,以降ではストリーム・プロセッサと呼ぶことにする〕が8個搭載されています.ストリーム・プロセッサはクロックごとに単精度の積和演算(1クロックで積算と加算の2演算が可能)を実行可能です.
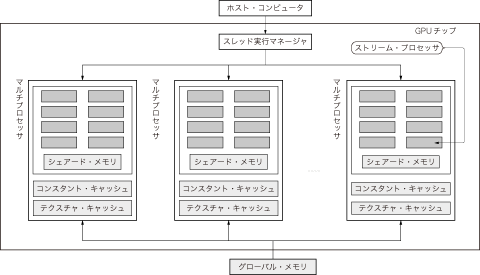
図2 CUDA対応GPUのハードウェア構成
「マルチプロセッサ」と呼ばれる回路ブロックが複数並んだ構成になっている.一つのマルチプロセッサの中には,「ストリーム・プロセッサ」が8個搭載されている.ストリーム・プロセッサはクロックごとに単精度の積和演算が実行可能である.
例えば,GeForce 8800 GTXは1.35GHz駆動のストリーム・プロセッサを128個搭載しており,ピーク性能で単精度345.6GFLOPS(1.35GHz×128プロセッサ×2演算)の演算能力を持ちます.一般的な数値計算では,ストリーム・プロセッサを中心に演算処理を行うことになります.これに加えて,グラフィックス処理に特化した機能がGPUに内蔵されており,この演算能力を合わせると,単体のGPUで500GFLOPS以上の性能となります.
CUDA対応GPUでは,ある計算処理を"スレッド"と呼ばれる単位に分割して,並列計算を行います.スレッド・スケジューラが,GPUのプログラムをスレッドに分割して,マルチプロセッサの中の8個のストリーム・プロセッサに割り当てていきます.マルチプロセッサの中の各ストリーム・プロセッサは,クロック・サイクルごとに,異なるデータに対して同一の命令を実行します.この意味で,マルチプロセッサはSIMD(Single-Instruction Multiple-Data)型プロセッサととらえることもできます.
GPUは種類によってマルチプロセッサの数やクロック周波数が異なります.これらの違いを表1にまとめます.現在,GPUのバージョンは2種類あり,バージョン1.0と1.1が存在します.本稿では詳しく述べませんが,バージョン1.1は,バージョン1.0ではサポートされていないアトミック・オペレーションが追加されました.
● 外部メモリとオンチップ・メモリを使い分ける
ストリーム・プロセッサへデータを滞りなく供給できなければ,GPUはその演算性能を発揮することができません.その演算性能を発揮できるように,CUDA対応GPUのメモリは,2種類存在します.一つはGPUボード上に実装されたGDDR3を使用した外部メモリ(デバイス・メモリ),もう一つはGPU内部のオンチップ・メモリです.表1のメモリ・バス幅とは,GPUと外部メモリの間のバス幅を示しています.
| ストリーム・プロセッサのクロック周波数(GHz) | ストリーム・プロセッサ数(マルチプロセッサ数) | メモリ・バス幅(ビット) | メモリ・クロック周波数(GHz) | バージョン | |
| GeForce 8800 Ultra | 1.5 | 128(16) | 384 | 2.16 | 1.0 |
| GeForce 8800 GTX | 1.35 | 128(16) | 384 | 1.8 | 1.0 |
| GeForce 8800 GTS | 1.2 | 96(12) | 320 | 1.6 | 1.0 |
| GeForce 8600 GTS | 1.45 | 32(4) | 128 | 2 | 1.1 |
| GeForce 8600 GT | 1.19 | 32(4) | 128 | 1.4 | 1.1 |


