CUDA技術を利用したGPUコンピューティングの実際(前編) ―― グラフィックス分野で磨かれた並列処理技術を汎用数値計算に応用
基本的な使い方では,外部メモリはホスト・コンピュータから送られてきたデータや計算結果などを格納するためのものです.大容量のデータを格納することができる反面,オンチップ・メモリに比べるとレイテンシ時間が長く,データ転送速度が遅いなどの欠点を持ちます.一方,オンチップ・メモリは小容量ですが,外部メモリに比べると非常に高速です.
さらに,外部メモリとオンチップ・メモリは用途別に幾つかの種類が存在します.これを表2にまとめます.ホストはデータの格納先として3種類のメモリ(グローバル・メモリ,テクスチャ・メモリ,コンスタント・メモリ)を選択できますが,本稿ではグローバル・メモリのみを使用します.ホストから読み書きできるメモリはグローバル・メモリだけなので,GPUの計算結果はグローバル・メモリへ格納しておき,GPUの計算終了後にホストがCUDAのAPI(Application Programming Interface)を使用して,計算結果をグローバル・メモリから回収することになり
ます.
シェアード・メモリ(共有メモリ)についてはマルチプロセッサごとに16Kバイト,レジスタについてはマルチプロセッサごとに32ビット・レジスタが8192個(つまり32Kバイト)実装されています.
テクスチャ・メモリとコンスタント・メモリについては,それぞれテクスチャ・キャッシュとコンスタント・キャッシュというキャッシュ・メモリにデータがキャッシングされます.ローカル・メモリとグローバル・メモリは,残念ながらキャッシングされません.表2のスコープについては後述します.
| メモリの種類 | GPU側からのアクセス | ホスト側からのアクセス | スコープ | |
| デバイス・メモリ | グローバル・メモリ | R/W | R/W | グリッド |
| コンスタント・メモリ | R | W | グリッド | |
| テクスチャ・メモリ | R | W | グリッド | |
| ローカル・メモリ | R/W | N/A | スレッド | |
| オンチップ・メモリ | シェアード・メモリ | R/W | N/A | ブロック |
| レジスタ | R/W | N/A | スレッド | |
| テクスチャ・キャッシュ | R | N/A | ブロック | |
| コンスタント・キャッシュ | R | N/A | ブロック | |
注;R/Wは読み書き可能,Rは読み出しのみ,Wは書き込みのみ,N/Aはアクセス不可.
● プログラムを細かく分割してプロセッサに振り分け
GPU上で実行するプログラムのことを「カーネル」と呼びます.ホスト・コンピュータが,このカーネルをGPUへ転送することで,GPUは計算を実行できます.カーネルは「グリッド」とも呼びます.
1)ブロックへの分割
GPUはこのグリッドを上手に分割して,マルチプロセッサやストリーム・プロセッサに並列処理を行わせます.抽象的な話となるので,ここではある配列A(N×Nサイズ)の各要素に1を加算する計算を例に,話を進めていきます(図3).この例の場合,計算全体をグリッドが担当することになります.
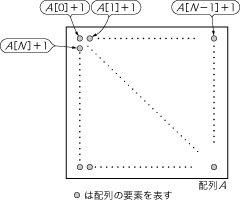
図3 配列の要素への加算の例
ある配列A(N×Nサイズ)の各要素に1を加算する.
GPUがグリッドを実行する際に,マルチプロセッサで並列処理を行うため,グリッドを複数の「ブロック」と呼ばれる単位に分割し,分割されたブロックをマルチプロセッサへ割り当てます(図4).一つのマルチプロセッサ当たり一つのブロックが割り当てられるわけではなく,マルチプロセッサ内の共有資源(レジスタやシェアード・メモリ)に余裕があれば,複数のブロックが一つのマルチプロセッサへ割り当てられます.
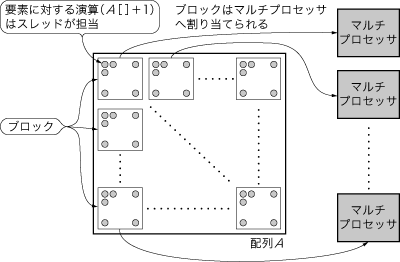
図4 グリッドのブロックへの分割
マルチプロセッサで並列処理を行うため,グリッドを複数の「ブロック」と呼ばれる単位に分割し,分割されたブロックをマルチプロセッサへ割り当てる.


