音声の分析・合成処理の基本 ―― 携帯電話やVoIPで使われている音声圧縮技術の仕組み
tag: 組み込み ディジタル・デザイン
技術解説 2010年8月27日
ここでは人が声を出すのと同じような仕組みで音声を処理する技術を取り上げます.携帯電話で使われている音声圧縮技術である分析合成方式について具体的に説明します.この方式では,PCMやADPCMなどの波形符号化方式よりも高い圧縮率を実現できます. (編集部)
※ 本記事は,ディジタル・デザイン・テクノロジ No.6から転載いたしました.同誌はこちらから購入できます.
本稿では,音声波形そのものを符号化する波形符号化方式とは異なり,音声の発生機構をモデル化し,そのパラメータを符号化する分析合成方式について説明します.この方式は,携帯電話やVoIPで用いられています.
1.分析合成方式の原理
音声の発声機構とそのモデルを図1に示します.
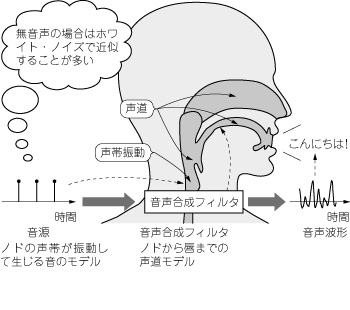
図1 音声の発声機構のモデル化
音源は比較的単純な波形としてモデル化できる.
人の発声では,まず,喉にある声帯が振動することにより,肺からの空気の流れが断続的になり,ブザーのような単調な音が生じます.これが音声の音源となります.そして,この音源が喉から唇までの声道を通過することで,「あ」や「い」などさまざまに特徴づけられた音声信号として発声されます.
●音源をモデル化して高い圧縮率を実現
実際に発声される音声は複雑な波形となりますが,その音源は比較的単純な波形としてモデル化できます.極端な例では,複雑な特性をすべて音声合成フィルタに含めるものとしてしまえば,図1のように音源を周期的なパルスの列としてモデル化することも可能です.
この単純なモデル化においては,
- 音源となるパルスの間隔(ピッチ周期)
- パルスの大きさ
- 音声再合成フィルタのフィルタ係数
だけで音声を表現できます.つまり,これら三つのパラメータだけを符号化して送信すればよいことになります.
さらに,音声は20ms~40ms程度の短時間であれば,ほとんど変化しないことが知られています(1).つまり,これら三つのパラメータを一定時間ごとに1回だけ送信すればよいことになります.
この特徴を用いることで,高い圧縮率を実現することができます(図2).
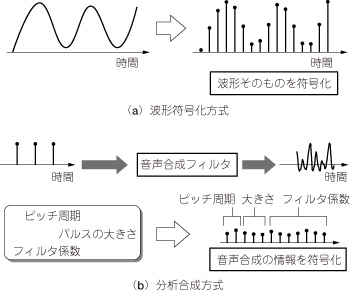
図2 波形符号化方式と分析合成方式の違い
波形符号化方式では波形そのものを符号化する.これに対して分析合成方式ではピッチ周期やパルスの大きさ,フィルタ係数などを符号化する.


