新人技術者のためのロジカル・シンキング入門(9) ―― メモリ転送速度の最適化設計
【2】フロー全体を見渡した最適化が必要(1/2)
ところで,パイプライン化というのは概念としてはシンプルですが,実際にコーディングに反映するとなると,なかなか難しいものとなります.
プログラマはまず,DMA転送とCPU処理のタイム・チャートを調べ,両者をうまく配置できるような設計を考えなければなりません(図3).
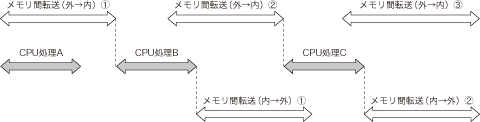
図3 転送のタイミング・チャート
DMA転送とCPU処理をうまく最適化するためには,転送のタイム・チャートを検討し,互いに依存する転送と処理は前後関係が矛盾しないようにうまくパイプラインを組む必要がある.これはプログラム・フロー全体を見通す必要がある作業である.
これは,
- DMAとCPUがなるべく同時処理を行えるように配置する
- 互いに依存する処理は前後関係を正しく配置する
という二つの要請をともに満たすように,DMA転送とCPU処理を配置していく作業です.
同時処理を行えるように配置されていなければ,処理速度の十分な向上は見込めません.かといって,互いに依存する処理の前後関係が矛盾していると,処理済みのデータを上書きしてしまったり,内部メモリで行った処理が外部メモリに反映されなかったり,といったことが生じてしまいます.ここを見落とすと,冒頭の例で挙げた「モンスターが壁にぶつかると崩れてしまう」といったような,最適化によるバグ混入を生んでしまうのです.
やっかいなのは,このパイプライン化というのが,プログラム・フロー全体を見通した上で行わなければならない作業であることです.
前回に挙げたようなアセンブリ・コードによる最適化は,最適化の対象となる関数の中に閉じた作業です.従って,その関数が単体で最適化後も正しく動作することさえ確認できれば,その最適化がほかの個所に影響を及ぼす心配はないと言えます.
もちろん,アセンブリ・コードによる最適化自体は極めて難易度の高いものです.しかし,最適化後の動作確認はそれほど難しくないと言えるでしょう.なぜなら,アセンブリ・コードによる最適化は,既に述べたように,常に関数単体に閉じて行うことができるからです.従って,最適化した関数が完ぺきならば,残りのブロックが影響を受けることはありません.
ところが,ここで述べているパイプライン化というのは,プログラム・フロー全体を見通す必要があるものです.従って,最適化が十分になされているか,最適化によるバグが生じないかを,常にプログラム全体を見通して確認する必要があります.
tag: 技術教育


