ハードウェアを意識したプログラミングの基礎(後編)
さてGCCには,この詰め物を外すための方法があります.リスト5の6行目にある構造体の宣言に「__attribute__((__packed__))」という属性を付けました.この属性が付いた構造体は詰め物が外され,純粋に構造体のメンバ変数だけで構成されるようになります.実行してみましょう.
1: #include <stdio.h>
2:
3: struct test_t {
4: char a;
5: int b;
6: } __attribute__((__packed__));
7:
8: struct test_t test = {0x10, 0x20};
9:
10: int main()
11: {
12: int val;
13:
14: val = test.b;
15: printf("%08x\", val);
16: printf("test: %p\", &test);
17: printf("test.b: %p\", &test.b);
18:
19: return 0;
20: }
リスト5 詰め物を外す
./unaligned-struct-offset-packed
00000020
test: 0x80495c0
test.b: 0x80495c1
オフセットが1バイトに変わりました.つまり,メンバ変数bは,図2のようになっています.test.bへのアクセスはアラインメントが合っていませんが,x86なので正しい値がとれているようです.
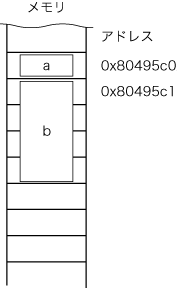
図2 構造体のパック
さて,ここからが本番です.このコードをARMで動かすとどうなるのでしょう? おや? アラインメントが合っていないのに正しくとれているようです.どうしてでしょう? 答えはもちろんバイナリにあります.main()を逆アセンブルしてみましょう(リスト6).
1: 000084d8 <main>:
2: 84d8: e92d4010 stmdb sp!, {r4, lr}
3: 84dc: e59f4040 ldr r4, [pc, #64] ; 8524 <.text+0x198>
4: 84e0: e5d43002 ldrb r3, [r4, #2]
5: 84e4: e5d41001 ldrb r1, [r4, #1]
6: 84e8: e5d40003 ldrb r0, [r4, #3]
7: 84ec: e1811403 orr r1, r1, r3, lsl #8
8: 84f0: e5d42004 ldrb r2, [r4, #4]
9: 84f4: e1811800 orr r1, r1, r0, lsl #16
10: 84f8: e1811c02 orr r1, r1, r2, lsl #24
11: 84fc: e59f0024 ldr r0, [pc, #36] ; 8528 <.text+0x19c>
12: 8500: ebffff9b bl 8374 <.text-0x18>
リスト6 main()を逆アセンブルする
重要なのは,4,5,6,8行目です.
4:84e0: e5d43002 ldrb r3, [r4, #2]
5:84e4: e5d41001 ldrb r1, [r4, #1]
6:84e8: e5d40003 ldrb r0, [r4, #3]
8:84f0: e5d42004 ldrb r2, [r4, #4]
3行目でr4にロードしたグローバル変数testのアドレスを使って,1バイトずつロードしているのが見えます.その後,一つ一つ論理和(orr)をとっています(7,9,10行目).
7:84ec: e1811403 orr r1, r1, r3, lsl #8
9:84f4: e1811800 orr r1, r1, r0, lsl #16
10:84f8: e1811c02 orr r1, r1, r2, lsl #24
確かにこの方法なら値は正しく読めます.しかし,前にも例に出しているように,デバイスにアクセスするときには問題になります.
また,速度的にも問題になるかもしれません(図3).リスト7のコードは,パックしていないバージョンです.
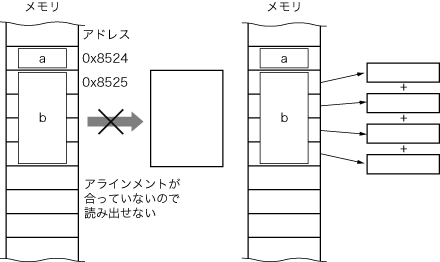
図3 ARMのメモリ・アクセス
1: 000084d8 <main>:
2: 84d8: e92d4010 stmdb sp!, {r4, lr}
3: 84dc: e59f4028 ldr r4, [pc, #40] ; 850c <.text+0x180>
4: 84e0: e59f0028 ldr r0, [pc, #40] ; 8510 <.text+0x184>
5: 84e4: e5941004 ldr r1, [r4, #4]
6: 84e8: ebffffa1 bl 8374 <.text-0x18>
リスト7 パックしない場合
3行目でtestのアドレスをr4にロードし,次にprintfの第1引き数%08x\のアドレスをr0にロードします.最後にr4を使ってtest.bの値をr1にロードし,printfにジャンプしています.printfまで10命令かかっていたのが,4命令で終わってしまいます.
このようにアラインメントが合っていないアクセスは,意図しないアクセスを生成したり,正しいコード生成のために速度を犠牲にしたりします.
● get_unaligned
Linuxは基本的にCPUのアラインメントを尊重しています.ですからアラインメントが正しくそろうようにデバイス・ドライバを書かなければなりません.しかし,どうしてもアラインメントがずれているアクセスが必要な場合もあるかもしれません.そのようなときはLinuxが提供している次のマクロを使うことができます.
include/asm-arm/unaligned.h
include/asm-powerpc/unaligned.h
include/asm-x86/unaligned_32.h
使い方は,
get_unaligned(val, ptr);
とします.アラインメントがずれていても問題のない x86とPowerPCは空のマクロになるようになっています.ARMではリスト8のように定義されています.__builtin_choose_exprはC言語の条件演算子(?:)だと考えてください.ポインタが指している型のサイズによって別のマクロ(__get_unaligned_X_le)が呼ばれるようになっています.サイズが1のときはそのまま値を返します.2のときは,
#define __get_unaligned_2_le(__p) (__p
[0] | __p[1] << 8)
のように1バイト目と2バイト目を入れ換えるようになっています.ほかのサイズでも同じようになっています.ただし,1,2,4,8以外のサイズが与えられた場合は,__bug_unaligned_x()が呼ばれるようになっています.この__bug_unaligned_xはヘッダ・ファイルでexternとなっていますが,実体はありません.つまり,コンパイル・エラーになるようになっています.
#define __get_unaligned_le(ptr) \
((__force typeof(*(ptr)))({ \
const __u8 *__p = (const __u8 *)(ptr); \
__builtin_choose_expr(sizeof(*(ptr)) == 1, *__p, \
__builtin_choose_expr(sizeof(*(ptr)) == 2, __get_unaligned_2_le(__p), \
__builtin_choose_expr(sizeof(*(ptr)) == 4, __get_unaligned_4_le(__p), \
__builtin_choose_expr(sizeof(*(ptr)) == 8, __get_unaligned_8_le(__p), \
(void)__bug_unaligned_x(__p))))); \
}))
リスト8 ARMでのget_unaligned()の定義


