ハードウェアを意識したプログラミングの基礎(前編)
1: #include <stdio.h>
2: #include <linux/types.h>
3: #include <asm/byteorder.h> ←ヘッダを追加
4:
5: int main()
6: {
7: char fifo[] = {0x12, 0x34, 0xAB, 0xCD};
8: __u32 val;
9:
10: val = __le32_to_cpu(*(__u32 *)fifo); ←マクロを使用
11:
12: printf("0x%Xエn", val);
13: return 0;
14: }
リスト2 asm/byteorder.hを使った例
リスト2がその修正を入れたコードです.3行目で新しく asm/byteorder.hをインクルードし,10行目でマクロ__le32_to_cpu()を使っています注3.
注3;ポインタを扱う __le32_to_cpup()もあるが,ここでは説明を簡単にするために__le32_to_cpu()を使う.
では実際にマクロがどのようになっているかを見てみましょう注4.まずは,x86のようにCPUがリトル・エンディアンの場合です.この場合,読み込みは既にリトル・エンディアンで行われるため,変換は必要ありません.そのため,little_endian.hで定義されているle32_to_cpuに影響を与えないように消えてしまいます.
注4;説明用にSparse用のマクロなどを外して簡素化している.SparseとはSemantec PARSErの略で,Linux Kernel用に開発された静的コード解析ツール.URL:http://www.kernel.org/pub/software/devel/sparse
#define __le32_to_cpu(x) (x)
PowerPCのようなビッグ・エンディアンのCPUの場合は,以下のように展開されます.
#define __cpu_to_le32(x) (__swab32(x))
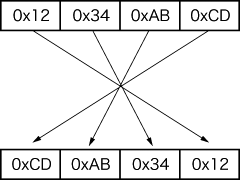
図4 マクロ__swab32
__swab32が実際にバイトの入れ替えを行うマクロです(図4).このマクロは,高速版を提供しているアーキテクチャでは高速版を,それ以外では一般的な方法を使うようになっています.一般的な方法は「_」が一つ増えた名前で,
include/linux/byteorder/swab.h
の中でリスト3のように定義されています.32ビットの変数から8ビットを四つ取り出し,並び換えているのが分かります.
static __inline__ __u32 ___swab32(__u32 x)
{
return x<<24 | x>>24 |
(x & (__u32)0x0000ff00UL)<<8 |
(x & (__u32)0x00ff0000UL)>>8;
}
リスト3 マクロ___swab32の定義
2.I/Oアクセス
エンディアンの次に気を付ける点といえば,アーキテクチャによってCPUとデバイスの接続方法が異なり,アクセス方法も異なることです.
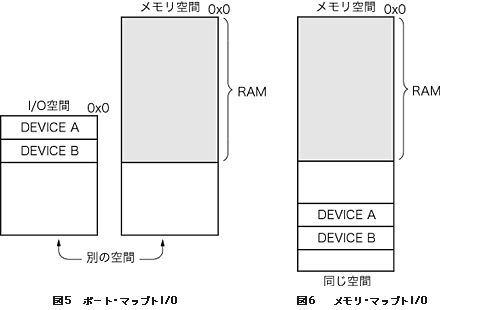
x86で採用されているアクセス方法をポート・マップトI/Oと呼びます.この方法は,メモリ・アクセス命令とデバイス・アクセス命令を完全に別にすることで,二つのアドレス空間を完全に分けてしまいます(図5).これにより,メモリだけでアドレス空間を占有することが可能です.アドレス空間が小さかったころは有効な手段でした.またアセンブリ言語を一目見るだけで,メモリにアクセスしているのかデバイスにアクセスしているのかを判断できるという利点もあります注5.
注5;最近はあまりアセンブリ言語でガリガリと書かなくなったので,利点と言えるか疑問だが....
これとは対照的に,ARMやPowerPC,MicroBlazeなどで採用されているのがメモリ・マップトI/Oという形式です注6.これは,デバイスのアドレス空間をメモリのアドレス空間に重ね,一つの空間に共存させる方法です(図6).


